La spectroscopie infrarouge proche (NIR) a été largement acceptée en tant que technologie d’analyse moderne rapide, efficace, non destructive et non polluante; la méthode a été utilisée au cours des dernières années pour la détection et l’analyse de la qualité des produits et la mesure des composants chimiques dans les procédés industriels. La spécialité la plus essentielle de la méthode est sa capacité à enregistrer des spectres pour les échantillons solides et liquides sans aucun pré-traitement, ce qui rend NIRS particulièrement adapté à la détection directe et rapide et l’analyse des produits naturels et synthétiques1,2. Contrairement aux capteurs traditionnels qui mesurent les variables du processus (p. ex. température, pression, niveau de liquide, etc.) à une échelle macroscopique et subissent inévitablement le bruit extérieur et l’interférence de fond, le NIRS détecte les informations structurelles de la composition chimique à des échelles microscopiques et moléculaires. Ainsi, l’information essentielle peut être mesurée avec plus de précision et de efficacité qu’avec d’autres méthodes3,4.
L’éther de polyphényle, comme l’un des plastiques d’ingénierie, sont largement employés en raison de sa résistance à la chaleur, retardant la flamme, isolation, propriétés électriques, stabilité dimensionnelle, résistance d’impact, résistance de fluage, force mécanique et d’autres propriétés5. Plus important encore, il est non toxique et inoffensif par rapport à d’autres plastiques d’ingénierie. À l’heure actuelle, 2,6-xylenol est l’une des matières premières de base pour la synthèse de l’éther de polyphénylène, et il est généralement préparé par alkylation catalysée du phénol avec la méthode de méthanol6. Il existe deux produits principaux de cette méthode de préparation, o-cresol et 2,6-xylenol. Après une série d’étapes de séparation et d’extraction, 2,6 xylenol est utilisé pour produire de l’éther de polyphénylène. Cependant, des quantités infimes d’o-cresol demeurent dans 2,6-xylenol. O-cresol ne participe pas à la synthèse de l’éther de polyphénylène et restera dans le produit d’éther de polyphénylène, ayant pour résultat une diminution de la qualité du produit ou même de la qualité inférieure. À l’heure actuelle, la plupart des entreprises analysent encore les compositions de mélanges organiques complexes tels que les produits d’éther de polyphényle de phase liquide contenant des impuretés (p. ex., o-cresol) par analyse de séparation physique ou chimique comme la chromatographie7,8. Le principe de séparation de la chromatographie est l’utilisation du mélange des compositions dans la phase fixe et la phase de flux dans la dissolution, l’analyse, l’adsorption, la desorption ou toute autre affinité des différences mineures dans la performance. Lorsque les deux phases se déplacent l’une par rapport à l’autre, les compositions sont séparées par les actions ci-dessus à plusieurs reprises dans les deux phases. Selon l’objet, il faut généralement quelques minutes à quelques dizaines de minutes pour effectuer une opération complexe de séparation des matériaux. On peut voir que l’efficacité de mesure est faible.
Aujourd’hui, la mesure de la qualité du produit et la technologie de contrôle avancée basée sur cette analyse pour l’industrie moderne des matériaux chimiques de procédé fin est la direction clé pour améliorer davantage la qualité du produit. Dans l’industrie des procédés de production d’éther de polyphényle, la mesure en temps réel de la teneur en o-crésol dans le produit d’éther de polyphénylène est d’une grande importance de développement. L’analyse chromatographique ne peut manifestement pas répondre aux exigences de la technologie de contrôle avancée pour la mesure en temps réel des substances et la rétroaction du signal. Par conséquent, nous proposons la méthode partielle de régression des moindres carrés (PLSR) pour établir un modèle linéaire entre les données NIRS et la concentration o-cresol, qui réalisent la mesure en ligne de la teneur en o-cresol dans le produit d’éther de polyphénylène liquide de sortie .
Le prétraitement du NIRS joue le rôle le plus important avant la modélisation statistique multivariée. Le nombre d’ondes NIRS dans le spectre NIR et la taille des particules des échantillons biologiques sont comparables, de sorte qu’il est connu pour les effets de dispersion inattendus qui ont une influence sur les spectres de l’échantillon enregistré. En exécutant des méthodes de prétraitement appropriées, ces effets sont faciles à éliminer en grande partie9. Les techniques de prétraitement les plus couramment utilisées dans le NIRS sont classées comme la correction de la diffusion et les méthodes dérivées spectrales. Le premier groupe de méthodes comprend la correction de dispersion multiplicative, la tendance, les transformations variates normales standard et la normalisation. Les méthodes de dérivation spectrale comprennent l’utilisation des premier et deuxième dérivés.
Avant d’élaborer un modèle de régression quantitative, il est important de supprimer les variations de dispersion non systématiques des données du NIRS parce qu’elles ont une influence significative sur l’exactitude du modèle prédictif, sa complexité et sa parcimonie. Le choix d’une méthode de prétraitement appropriée doit toujours dépendre de l’étape de modélisation ultérieure. Ici, si l’ensemble de données spectrales NIR ne suit pas la loi Lambert-Beer, alors d’autres facteurs tendent à compenser le comportement non idéal de la prédiction des composants prédits. L’inconvénient de l’existence de tels facteurs inutiles conduit à l’augmentation de la complexité du modèle, même très probablement, une réduction de la robustesse. Ainsi, l’application de dérivés spectrals et une normalisation conventionnelle des données spectrales est une partie essentielle de la méthode.
Après le prétraitement spectral, les données NIRS avec un rapport signal-bruit élevé et une faible interférence de fond sont obtenues. L’analyse Moderne de NIRS fournit l’acquisition rapide de grandes quantités d’absorption sur une gamme spectrale appropriée. La composition chimique de l’échantillon est ensuite prédite en extrayant les variables pertinentes à l’aide de l’information contenue dans la courbe spectrale. En général, NIRS est combiné avec des techniques d’analyse multivariées pour les analyses qualitatives ou quantitatives10. Une analyse multivariée de régression linéaire (MLR) est couramment utilisée pour développer et extraire la relation mathématique entre les données et les composants dans les processus industriels et a été largement utilisée dans l’analyse Du NIRS.
Cependant, il y a deux problèmes fondamentaux lors de la mise en œuvre d’un MLR pour les données NIRS prétraitées. Un problème est la redondance variable. La dimensionnalité élevée des données NIRS rend souvent la prédiction d’une variable dépendante peu fiable parce que les variables sont incluses qui n’ont aucune corrélation avec les composants. Ces variables redondantes réduisent l’efficacité de l’information des données spectrales et affectent l’exactitude du modèle. Afin d’éliminer la redondance variable, il est essentiel de développer et de maximiser la corrélation entre les données Du NIRS et les composants prévus.
Un autre problème est la question de la multicollinearité dans les données Du NIRS. L’une des hypothèses importantes des modèles de régression linéaire multiple est qu’il n’y a pas de relation linéaire entre l’une des variables explicatives du modèle de régression. Si cette relation linéaire existe, il est prouvé qu’il y a multicollinearity dans le modèle de régression linéaire et l’hypothèse est violée. Dans les régressions linéaires multiples, telles qu’une régression ordinaire des moindres carrés (OLSR), les corrélations multiples entre les variables affectent l’estimation du paramètre, augmentent l’erreur du modèle et affectent la stabilité du modèle. Pour éliminer la corrélation multilinéaire entre les données spectrales NIR, nous utilisons des méthodes de sélection variables qui maximisent la variabilité inhérente des échantillons.
Ici, nous proposons d’utiliser le PLSR, qui est une généralisation de la régression linéaire multiple qui a été largement utilisé dans le domaine de NIRS11,12. Le PLSR intègre les fonctions de base du MLR, de l’analyse canonique de corrélation (CCA) et de l’analyse des composants principaux (PCA) et combine l’analyse de prévision avec une analyse de connotation de données non-modèle. Le PLSR peut être divisé en deux parties. La première partie sélectionne les composants des variables caractéristiques et les composants prévus par analyse partielle des moindres carrés (PLS). PLS maximise la variabilité inhérente des composants principaux en rendant la covariance des principaux composants et des composants prévus aussi grand que possible lors de l’extraction des principaux composants. Ensuite, le modèle OLSR de concentration d’o-cresol est établi pour les principaux composants sélectionnés. PLSR convient à l’analyse de données bruyantes avec de nombreuses variables indépendantes qui sont fortement collinear et fortement corrélées et pour la modélisation simultanée de plusieurs variables de réponse. En outre, PLSR extrait l’information efficace des spectres d’échantillon, surmonte le problème de la multicollinearité, et a les avantages d’une forte stabilité et d’une haute précision de prédiction13,14.
Le protocole suivant décrit le processus d’utilisation du modèle PLSR pour mesurer la concentration d’o-cresol à l’aide de données spectrales NIR. La fiabilité et l’exactitude du modèle sont évaluées quantitativement en utilisant le coefficient de détermination (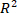 ), le coefficient de corrélation de prédiction (
), le coefficient de corrélation de prédiction (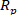 ) et l’erreur de prédiction carrée moyenne de la validation croisée (MSPECV). De plus, pour montrer intuitivement les avantages du PLSR, les indicateurs d’évaluation sont visualisés en plusieurs parcelles pour une analyse qualitative. Enfin, les indicateurs d’évaluation d’une expérience sont présentés sous forme de tableau pour illustrer quantitativement la fiabilité et la précision du modèle PLSR.
) et l’erreur de prédiction carrée moyenne de la validation croisée (MSPECV). De plus, pour montrer intuitivement les avantages du PLSR, les indicateurs d’évaluation sont visualisés en plusieurs parcelles pour une analyse qualitative. Enfin, les indicateurs d’évaluation d’une expérience sont présentés sous forme de tableau pour illustrer quantitativement la fiabilité et la précision du modèle PLSR.
