To produce sample results, we implemented the CaseOLAP algorithm in two subject headings/descriptors: "Age Groups" and "Nutritional and Metabolic Diseases" as use cases.
Age Groups. We selected all 4 subcategories of "Age Groups" (infant, child, adolescent, and adult) as cells in a Text-Cube. The obtained metadata and statistics are shown in Table 3A. The comparison of the number of documents among the Text-Cube cells is displayed in Figure 6A. Adult contains 172,394 documents which is the highest number across all cells. The adult and adolescent subcategories have the highest number of shared documents (26,858 documents). Notably, these documents included the entity of our interest only (i.e., mitochondrial proteins). The Venn diagram in Figure 6B represents the number of entities (i.e., mitochondrial proteins) found within each cell, and within multiple overlaps among the cells. The number of proteins shared within all Age Groups subcategories is 162. The adult subcategory depicts the highest number of unique proteins (151) followed by child (16), infant (8) and adolescent (1). We calculated the protein-age group association as a CaseOLAP score. The top 10 proteins (based on their average CaseOLAP score) associated with infant, child, adolescent and adult subcategories are Sterol 26-hydroxylase, Alpha-crystallin B chain, 25-hydroxyvitamin D-1 alpha-hydroxylase, Serotransferrin, Citrate synthase, L-seryl-tRNA, Sodium/potassium-transporting ATPase subunit alpha-3, Glutathione S-transferase omega-1, NADPH:adrenodoxin oxidoreductase, and Mitochondrial peptide methionine sulfoxide reductase (shown in Figure 6C). The adult subcategory displays 10 heatmap cells with a higher intensity compared to the heatmap cells of the adolescent, child and infant subcategory, indicating that the top 10 mitochondrial proteins exhibit the strongest associations to the adult subcategory. The mitochondrial protein Sterol 26-hydroxylase has high associations in all age subcategories which is demonstrated by heatmap cells with higher intensities compared to the heatmap cells of the other 9 mitochondrial proteins. The statistical distribution of the absolute difference in the score between two groups shows the following range for mean difference with a 99% confidence interval: (1) the mean difference between 'ADLT' and 'INFT' lies in the range (0.029 to 0.042), (2) the mean difference between 'ADLT' and 'CHLD' lies in the range (0.021 to 0.030), (3) the mean difference between 'ADLT' and 'ADOL' lies in the range (0.020 to 0.029), (4) the mean difference between 'ADOL' and 'INFT' lies in the range (0.015 to 0.022), (5) the mean difference between 'ADOL' and 'CHLD' lies in the range (0.007 to 0.010), (6) the mean difference between 'CHLD' and 'INFT' lies in the range (0.011 to 0.016).
Nutritional and Metabolic Diseases. We selected 2 subcategories of "Nutritional and Metabolic Diseases" (i.e., metabolic disease and nutritional disorders) to create 2 cells in a Text-Cube. The obtained metadata and statistics are shown in Table 3B. The comparison of the number of documents among the Text-Cube cells is displayed in Figure 7A. The subcategory metabolic disease contains 54,762 documents followed by 19,181 documents in nutritional disorders. The subcategories metabolic disease and nutritional disorders have 7,101 shared documents. Notably, these documents included the entity of our interest only (i.e., mitochondrial proteins). The Venn diagram in Figure 7B represents the number of entities found within each cell, and within multiple overlaps between the cells. We calculated the protein-"Nutritional and Metabolic Diseases" association as a CaseOLAP score. The top 10 proteins (based on their average CaseOLAP score) associated with this use case are Sterol 26-hydroxylase, Alpha-crystallin B chain, L-seryl-tRNA, Citrate synthase, tRNA pseudouridine synthase A, 25-hydroxyvitamin D-1 alpha-hydroxylase, Glutathione S-transferase omega-1, NADPH: adrenodoxin oxidoreductase, Mitochondrial peptide methionine sulfoxide reductase, Plasminogen activator inhibitor 1 (shown in Figure 7C). More than half (54%) of all proteins are shared between the subcategories metabolic diseases and nutritional disorders (397 proteins). Interestingly, almost half (43%) of all associated proteins in the metabolic disease subcategory are unique (300 proteins), whereas nutritional disorders exhibit only a few unique proteins (35). Alpha-crystallin B chain displays the strongest association to the subcategory metabolic diseases. Sterol 26-hydroxylase, mitochondrial displays the strongest association in the nutritional disorders subcategory, indicating that this mitochondrial protein is highly relevant in studies describing nutritional disorders. The statistical distribution of the absolute difference in the score between two groups 'MBD' and 'NTD' shows the range (0.046 to 0.061) for the mean difference as a 99% confidence interval.
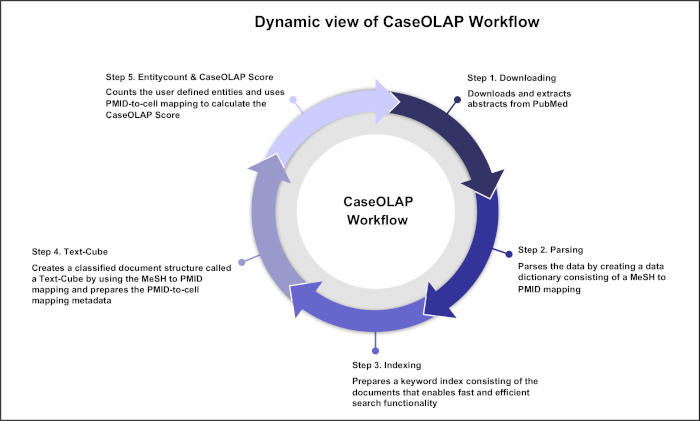
Figure 1. Dynamic view of the CaseOLAP Workflow. This figure represents the 5 major steps in the CaseOLAP workflow. In step 1, the workflow begins by downloading and extracting textual documents (e.g., from PubMed). In step 2, extracted data are parsed to create a data dictionary for each document as well as a MeSH to PMID mapping. In step 3, data indexing is conducted to facilitate fast and efficient entity search. In step 4, implementation of user-provided category information (e.g., root MeSH for each cell) is carried out to construct a Text-Cube. In step 5, the entity count operation is implemented over index data to calculate the CaseOLAP scores. These steps are repeated in an iterative manner to update the system with the latest information available in a public database (e.g., PubMed). Please click here to view a larger version of this figure.
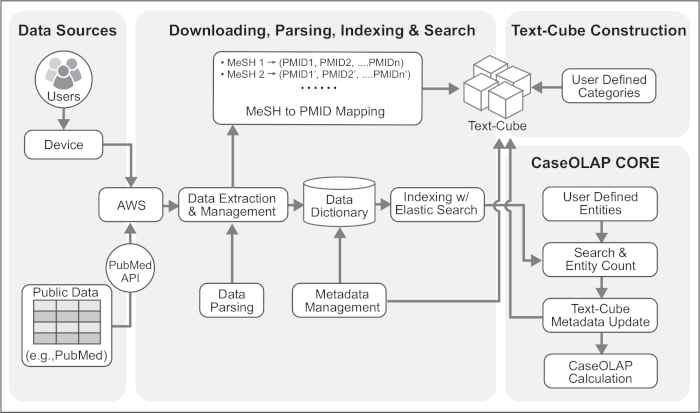
Figure 2. Technical Architecture of the CaseOLAP Workflow. This figure represents the technical details of the CaseOLAP workflow. Data from the PubMed repository are obtained from the PubMed FTP server. The user connects to the cloud server (e.g., AWS connectivity) via their device and creates a Download Pipeline which downloads and extracts the data to a local repository in the cloud. Extracted data are structured, verified, and brought to a proper format with a Data Parsing Pipeline. Simultaneously, a MeSH to PMID mapping table is created during the parsing step, which is used for Text-Cube construction. Parsed data are stored as a JSON like key-value dictionary format with document metadata (e.g., PMID, MeSH, publishing year). The Indexing step further improves the data by implementing Elasticsearch to handle bulk data. Next, the Text-Cube is created with user-defined categories by implementing MeSH to PMID mapping. When the Text-Cube formation and Indexing steps are completed, an entity count is conducted. Entity count data are implemented to the Text-Cube metadata. Finally, the CaseOLAP score is calculated based on the underlying Text-Cube structure. Please click here to view a larger version of this figure.

Figure 3. A sample of a parsed document. A sample of parsed data is presented in this figure. The parsed data are arranged as a key-value pair which is compatible with indexing and document metadata creation. In this figure, a PMID (e.g., "25896987") is serving as a key and collection of associated information (e.g., Title, Journal, Publishing date, Abstract, MeSH, Substances, Department and Location) are as value. The very first application of such document metadata is the construction of MeSH to PMID mapping (Figure 5 and Table 2), which is later implemented to create the Text-Cube and to calculate the CaseOLAP score with user-provided entities and categories. Please click here to view a larger version of this figure.
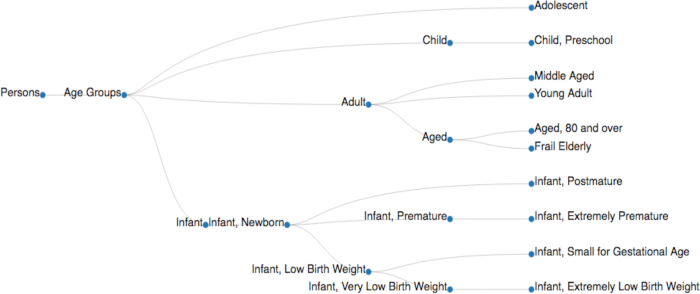
Figure 4. A sample of a MeSH tree. The 'Age Groups' MeSH tree is adapted from the tree data structure available in the NIH database (MeSH Tree 2018, <https://meshb.nlm.nih.gov/treeView>). MeSH descriptors are implemented with their node IDs (e.g., Persons [M01], Age Groups [M01.060], Adolescent [M01.060.057], Adult [M01.060.116], Child [M01.060.406], Infant [M01.060.703]) to collect the documents relevant to a specific MeSH descriptor (Table 3A). Please click here to view a larger version of this figure.
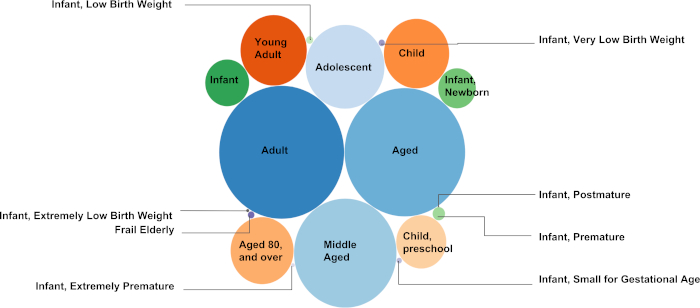
Figure 5. MeSH to PMID mapping in Age Groups. This figure presents the number of text documents (each linked with a PMID) collected under the MeSH descriptors in "Age Groups" as a bubble plot. The MeSH to PMID mapping is generated to provide the exact number of documents collected under the MeSH descriptors. A total number of 3,062,143 unique documents were collected under the 18 descendent MeSH descriptors (see Table 2). The higher the number of PMIDs selected under a specific MeSH descriptor, the larger the radius of the bubble representing the MeSH descriptor. For instance, the highest number of documents were collected under the MeSH descriptor "Adult" (1,786,371 documents), whereas the fewest number of text documents were collected under the MeSH descriptor "Infant, Postmature" (62 documents).
An additional example of MeSH to PMID mapping is given for "Nutritional and Metabolic Diseases" (https://caseolap.github.io/mesh2pmid-mapping/bubble/meta.html). A total number of 422,039 unique documents were collected under the 361 descendent MeSH descriptors in "Nutritional and Metabolic Diseases". The highest number of documents were collected under the MeSH descriptor "Obesity" (77,881 documents) followed by "Diabetes Mellitus, Type 2" (61,901 documents), whereas "Glycogen Storage Disease, Type VIII" exhibited the fewest number of documents (1 document). A related table is also available online at (https://github.com/CaseOLAP/mesh2pmid-mapping/blob/master/data/diseaseall.csv). Please click here to view a larger version of this figure.
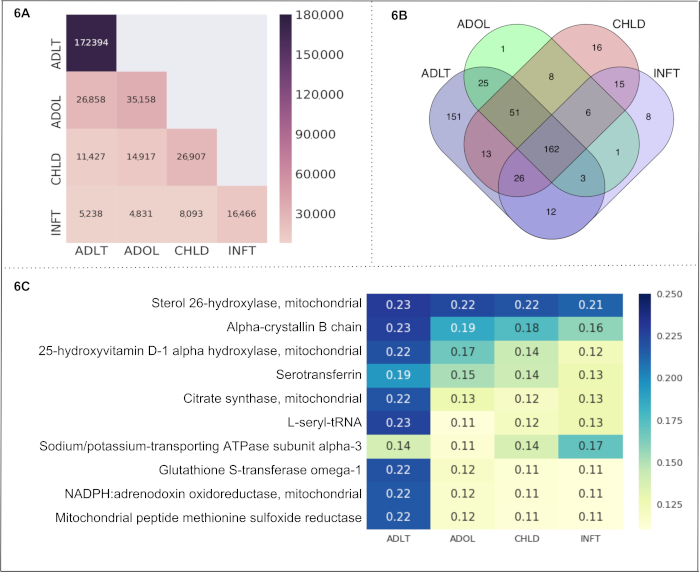
Figure 6. "Age Groups" as a use case. This figure presents the results from a use case of the CaseOLAP platform. In this instance, protein names and their abbreviations (see sample in Table 4) are implemented as entities and "Age Groups" including the cells: infant (INFT), child (CHLD), adolescent (ADOL), and adult (ADLT), are implemented as subcategories (see Table 3A). (A) Number of documents in "Age Groups": This heat map shows the number of documents distributed across the cells of "Aged Groups" (for details on the Text-Cube creation see Protocol 4 and Table 3A). A higher number of documents is presented with a darker intensity of the heatmap cell (see the scale). A single document may be included in more than one cell. The heatmap presents the number of documents within a cell along the diagonal position (e.g., ADLT contains 172,394 documents which is the highest number across all cells). The nondiagonal position represents the number of documents falling under two cells (e.g., ADLT and ADOL have 26,858 shared documents). (B). Entity count in "Age Groups": The Venn diagram represents the number of proteins found in the four cells representing "Age Groups" (INFT, CHLD, ADOL, and ADLT). The number of proteins shared within all cells is 162. The age group ADLT depicts the highest number of unique proteins (151) followed by CHLD (16), INFT (8) and ADOL (1). (C) CaseOLAP score presentation in "Age Groups": The top 10 proteins with the highest average CaseOLAP scores in each group are presented in a heat map. A higher CaseOLAP score is presented with a darker intensity of the heatmap cell (see the scale). The protein names are displayed on the left column and the cells (INFT, CHLD, ADOL, ADLT) are displayed along the x-axis. Some proteins show a strong association to a specific age group (e.g., Sterol 26-hydroxylase, alpha-crystallin B chain and L-seryl-tRNA have strong associations with ADLT, whereas Sodium/potassium-transporting ATPase subunit alpha-3 has a strong association with INFT). Please click here to view a larger version of this figure.
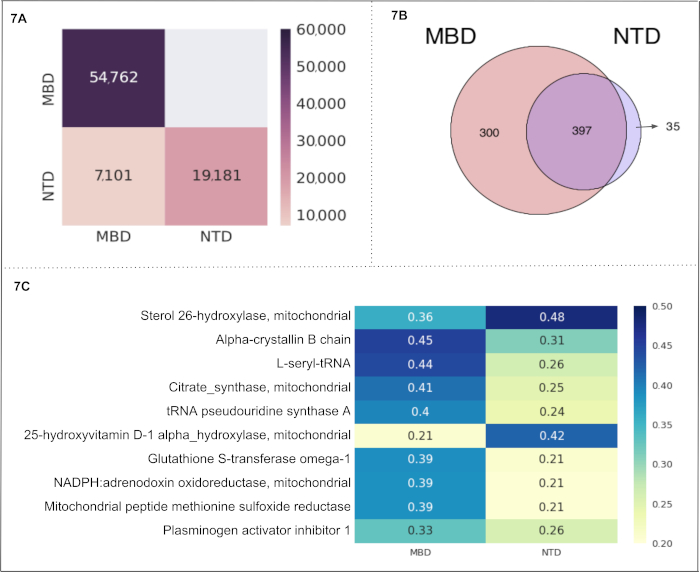
Figure 7. "Nutritional and Metabolic Diseases" as a use case: This figure presents the results from another use case of the CaseOLAP platform. In this instance, protein names and their abbreviations (see sample at Table 4) are implemented as entities and "Nutritional and Metabolic Disease" including the two cells: metabolic disease (MBD) and nutritional disorders (NTD) are implemented as subcategories (see Table 3B). (A). Number of documents in "Nutritional and Metabolic Diseases": This heatmap depicts the number of text documents in the cells of "Nutritional and Metabolic Diseases" (for details on the Text-Cube creation see Protocol 4 and Table 3B). A higher number of documents is presented with a darker intensity of the heatmap cell (see scale). A single document may be included in more than one cell. The heatmap presents the total number of documents within a cell along the diagonal position (e.g., MBD contains 54,762 documents which is the highest number across the two cells). The nondiagonal position represents the number of documents shared by the two cells (e.g., MBD and NTD have 7,101 shared documents). (B). Entity Count in "Nutritional and Metabolic Diseases": The Venn diagram represents the number of proteins found in the two cells representing "Nutritional and Metabolic Diseases" (MBD and NTD). The number of proteins shared within the two cells is 397. The MBD cell depicts 300 unique proteins, and the NTD cell depicts 35 unique proteins. (C). CaseOLAP score presentation in "Nutritional and Metabolic Diseases": The top 10 proteins with the highest average CaseOLAP scores in "Nutritional and Metabolic Diseases" are presented in a heat map. A higher CaseOLAP score is presented with a darker intensity of the heatmap cell (see scale). The protein names are displayed on the left column and cells (MBD and NTD) are displayed along the x-axis. Some proteins show a strong association to a specific disease category (e.g., alpha-crystallin B chain has a high association with metabolic disease and sterol 26-hydroxylase has a high association with nutritional disorders). Please click here to view a larger version of this figure.
| Time spent (percentage of total time) | Steps in the CaseOLAP platform | Algorithm and Data Structure of the CaseOLAP platform | Complexity of Algorithm and Data Structure | Details of the Steps |
| 40% | Downloading and Parsing |
Iteration and tree parsing algorithms | Iteration with nested loop and constant multiplication: O(n^2), O(log n). Where ‘n’ is no of iterations. | The Downloading pipeline iterates each procedure over multiple files. Parsing of a single document runs each procedure over the tree structure of raw XML data. |
| 30% | Indexing, Searching and Text Cube Creation | Iteration, Search algorithms by Elasticsearch (sorting, Lucene index, priority queues, finite state machines, bit twiddling hacks, regex queries) | Complexity related to Elasticsearch (https://www.elastic.co/) | Documents are indexed by implementing the iteration process over the data dictionary. The Text-Cube creation implements document meta-data and user-provided category information. |
| 30% | Entity Counting and CaseOLAP Calculation | Iteration in Integrity, Popularity, Distinctiveness calculation | O(1), O(n^2), multiple complexities related to caseOLAP Score calculation based on iteration types. | Entity count operation lists the documents and make an count operation over the list. The entity count data is used to calculate CaseOLAP score. |
Table 1. Algorithms and Complexities. This table presents information on the time spent (percentage of total time spent) on the procedures (e.g., downloading, parsing), data structure and details about the implemented algorithms in the CaseOLAP platform. CaseOLAP implements the professional indexing and search application called Elasticsearch. Additional information on complexities related to Elasticsearch and internal algorithms can be found at (https://www.elastic.co).
| MeSH descriptors | Number of of PMIDs collected |
| Adult | 1,786,371 |
| Middle Aged | 1,661,882 |
| Aged | 1,198,778 |
| Adolescent | 706,429 |
| Young Adult | 486,259 |
| Child | 480,218 |
| Aged, 80 and over | 453,348 |
| Child, Preschool | 285,183 |
| Infant | 218,242 |
| Infant, Newborn | 160,702 |
| Infant, Premature | 17,701 |
| Infant, Low Birth Weight | 5,707 |
| Frail Elderly | 4,811 |
| Infant, Very Low Birth Weight | 4,458 |
| Infant, Small for Gestational Age | 3,168 |
| Infant, Extremely Premature | 1,171 |
| Infant, Extremely Low Birth Weight | 1,003 |
| Infant, Postmature | 62 |
Table 2. MeSH to PMID mapping statistics. This table presents all descendant MeSH descriptors from “Age Groups” and their number of collected PMIDs (text documents). The visualization of these statistics is presented in Figure 5.
| A | Infant (INFT) | Child (CHLD) | Adolescent (ADOL) | Adult (ADLT) |
| MeSH root ID | M01.060.703 | M01.060.406 | M01.060.057 | M01.060.116 |
| Number of descendant MeSH descriptors | 9 | 2 | 1 | 6 |
| Number of PMIDs selected | 16,466 | 26,907 | 35,158 | 172,394 |
| Number of entities found | 233 | 297 | 257 | 443 |
| B | Metabolic Diseases (MBD) | Nutritional Disorders (NTD) | ||
| MeSH root ID | C18.452 | C18.654 | ||
| Number of descendant MeSH descriptors |
308 | 53 | ||
| Number of PMIDs collected | 54,762 | 19,181 | ||
| Number of entities found | 697 | 432 |
Table 3. Text-Cube Metadata. A tabular view of Text-Cube metadata is presented. The tables provide information about the categories and MeSH descriptor roots and descendants, which are implemented to collect the documents in each cell. The table also provides the statistics of the collected documents and entities. (A) “Age Groups”: This is a tabular display of “Age Groups” including infant (INFT), child (CHLD), adolescent (ADOL), and adult (ADLT) and their MeSH root IDs, number of descendant MeSH descriptors, number of selected PMIDs and number of found entities. (B) “Nutritional and Metabolic Diseases”: This is a tabular display of “Nutritional and Metabolic Diseases” including metabolic disease (MBD) and nutritional disorders (NTD) with their MeSH root IDs, number of descendant MeSH descriptors, number of selected PMIDs and the number of found entities.
| Protein names and Synonyms | Abbreviations |
| N-acetylglutamate synthase, mitochondrial, Amino-acid acetyltransferase, N-acetylglutamate synthase long form; N-acetylglutamate synthase short form; N-acetylglutamate synthase conserved domain form] | (EC 2.3.1.1) |
| Protein/nucleic acid deglycase DJ-1 (Maillard deglycase) (Oncogene DJ1) (Parkinson disease protein 7) (Parkinsonism-associated deglycase) (Protein DJ-1) | (EC 3.1.2.-) (EC 3.5.1.-) (EC 3.5.1.124)(DJ-1) |
| Pyruvate carboxylase, mitochondrial (Pyruvic carboxylase) | (EC 6.4.1.1)(PCB) |
| Bcl-2-binding component 3 (p53 up-regulated modulator of apoptosis) | (JFY-1) |
| BH3-interacting domain death agonist [BH3-interacting domain death agonist p15 (p15 BID); BH3-interacting domain death agonist p13 ; BH3-interacting domain death agonist p11 ] | (p22 BID) (BID) (p13 BID)(p11 BID) |
| ATP synthase subunit alpha, mitochondrial (ATP synthase F1 subunit alpha) | |
| Cytochrome P450 11B2, mitochondrial (Aldosterone synthase) (Aldosterone-synthesizing enzyme) (CYPXIB2) (Cytochrome P-450Aldo) (Cytochrome P-450C18) (Steroid 18-hydroxylase) | (ALDOS) (EC 1.14.15.4) (EC 1.14.15.5) |
| 60 kDa heat shock protein, mitochondrial (60 kDa chaperonin) (Chaperonin 60) (CPN60) (Heat shock protein 60) (Mitochondrial matrix protein P1) (P60 lymphocyte protein) | (HSP-60) (Hsp60) (HuCHA60)(EC 3.6.4.9) |
| Caspase-4 (ICE and Ced-3 homolog 2) (Protease TX) [Cleaved into: Caspase-4 subunit 1; Caspase-4 subunit 2] | (CASP-4) (EC 3.4.22.57)(ICH-2) (ICE(rel)-II) (Mih1) |
Table 4. Sample Entity Table. This table presents the sample of entities implemented in our two use cases: “Age Groups” and “Nutritional and Metabolic Diseases” (Figure 6 and Figure 7, Table 3A,B). The entities include protein names, synonyms, and abbreviations. Each entity (with its synonyms and abbreviations) is selected one by one and is passed through the entity search operation over indexed data (see protocol 3 and 5). The search produces a list of documents which further facilitate the entity count operation.
| Quantities | User Defined | Calculated | Equation of the quantity | Meaning of the quantity |
| Integrity | Yes | No | Integrity of user defined entities considered to be 1.0. | Represents a meaningful phrase. Numerical value is 1.0 when it is already an established phrase. |
| Popularity | No | Yes | Popularity equation in Figure 1 (Workflow and Algorithm) from reference 5, 'Materials and Methods' section. | Based on term frequency of the phrase within a cell. Normalized by total term frequency of the cell. Increase in term frequency has diminishing result. |
| Distinctiveness | No | Yes | Distinctiveness equation in Figure 1 (Workflow and Algorithm) from reference 5, 'Materials and Methods' section. | Based on term frequency and document frequency within a cell and across the neighbouring cells. Normalized by total term frequency and document frequency. Quantitatively, it is the probability that a phrase is unique in a specific cell. |
| CaseOLAP score | No | Yes | CaseOLAP score equation in Figure 1 (Workflow and Algorithm) from reference 5, 'Materials and Methods' section. | Based on Integrity, Popularity, and Distinctiveness. Numerical value always falls within 0 to 1. Quantitatively the CaseOLAP score represents the phrase-category association |
Table 5. CaseOLAP equations: The CaseOLAP algorithm was developed by Fangbo Tao and Jiawei Han et al. in 20161. Briefly, this table presents the CaseOLAP score calculation consisting of three components: integrity, popularity, and distinctiveness, and their associated mathematical meaning. In our use cases, the integrity score for proteins is 1.0 (the maximum score) because they stand as established entity names. The CaseOLAP scores in our use cases can be seen in Figure 6C and Figure 7C.
