Six different queries performed on realistic standardized EHR extracts containing information about the problems of patients, including their names, initial and final dates and severity, are shown in Table 1.
Average response times of the six queries in the three doubling-size databases in each DBMS are shown in Tables 2-4. Figures 1-6 show the same results graphically (notice that the vertical axes use very different scales throughout these figures).
The strong linear behavior of computational complexity is evident throughout all queries of the NoSQL databases, although with appropriate caution due to the relatively small size of the 3 datasets used. However, the relational ORM database shows an unclear linear behavior. The MongoDB database has a much flatter slope than the eXist database.
Results by the improved relational systems discussed in the introduction published in the literature may be found in Table 5. Interpolating MongoDB results from Table 3 with similar queries and database sizes of ARM results from Table 5 equals both database systems in Q1, but favors MongoDB in Q3.
The results of the concurrency experiments may be found in Table 5 and Table6. MongoDB beats MySQL both in throughput and response time. In fact, MongoDB behaves better in concurrency than in isolation, and stands as an impressive database in concurrent execution.
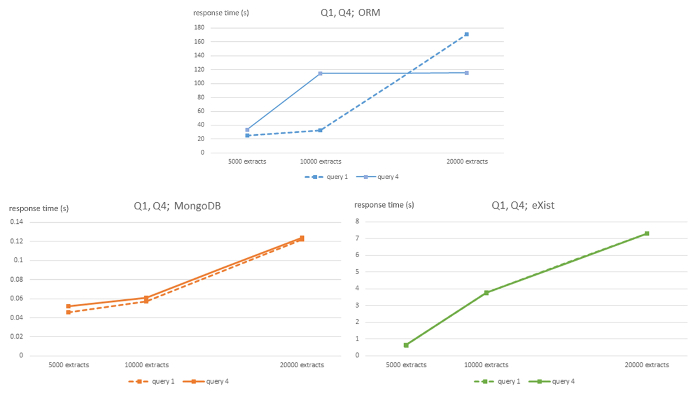
Figure 1: Algorithmic complexity of ORM MySQL, MongoDB, and eXist DBMS for queries Q1 and Q4. This figure has been modified from7 using Creative Commons license (http://creativecommons.org/ licenses/by/4.0/) and shows response times in seconds for 5,000, 10,000 and 20,000-sized EHR extracts databases for each DBMS and queries Q1 and Q4. Please click here to view a larger version of this figure.
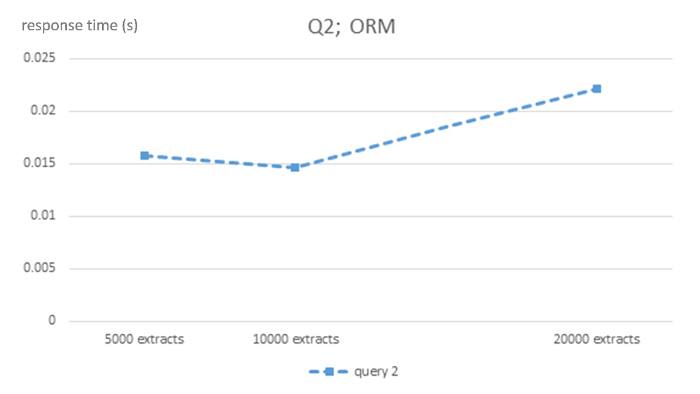
Figure 2: Algorithmic complexity of ORM MySQL DBMS for query Q2. This figure shows response times in seconds for 5,000, 10,000 and 20,000-sized EHR extracts ORM MySQL database for query Q2. Please click here to view a larger version of this figure.
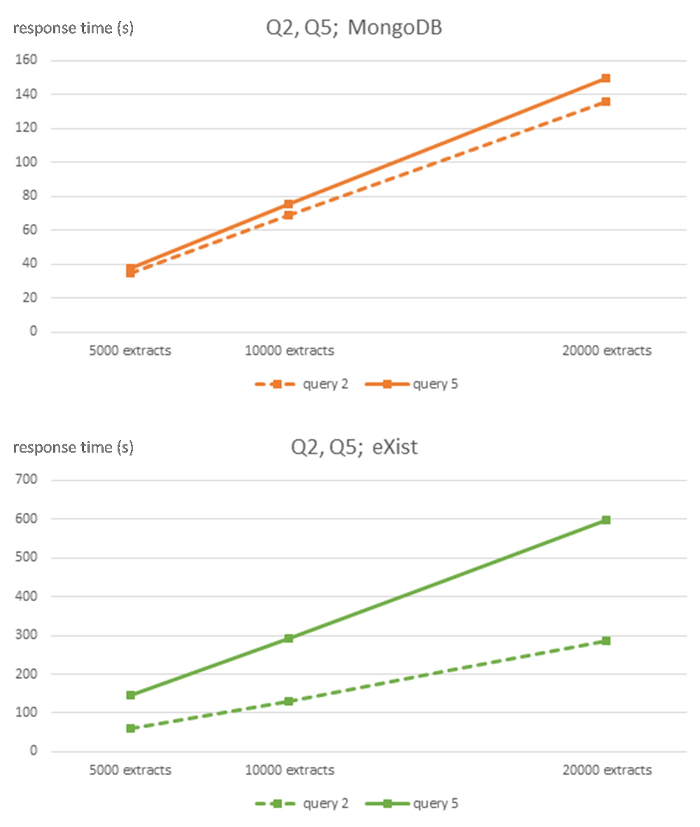
Figure 3: Algorithmic complexity of MongoDB and eXist DBMS for queries Q2 and Q5. This figure has been modified from7 using Creative Commons license (http://creativecommons.org/licenses/ by/4.0) and Shows response times in seconds for 5,000, 10,000, and 20,000-sized EHR extracts databases for each DBMS and queries Q2 and Q5. Please click here to view a larger version of this figure.
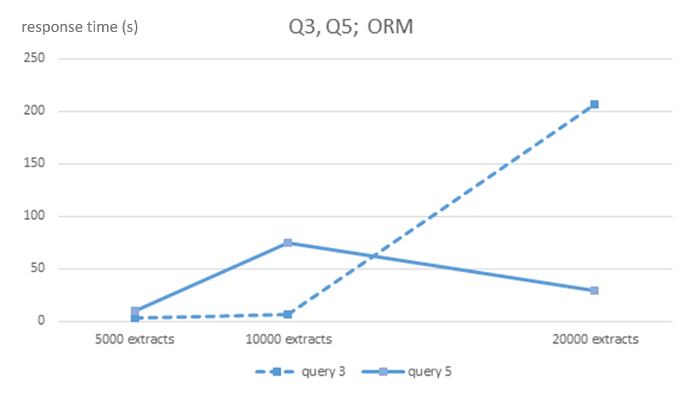
Figure 4: Algorithmic complexity of ORM MySQL DBMS for queries Q3 and Q5. Shows response times in seconds for 5,000, 10,000 and 20,000-sized EHR extracts databases for each DBMS and queries Q3 and Q5. Please click here to view a larger version of this figure.
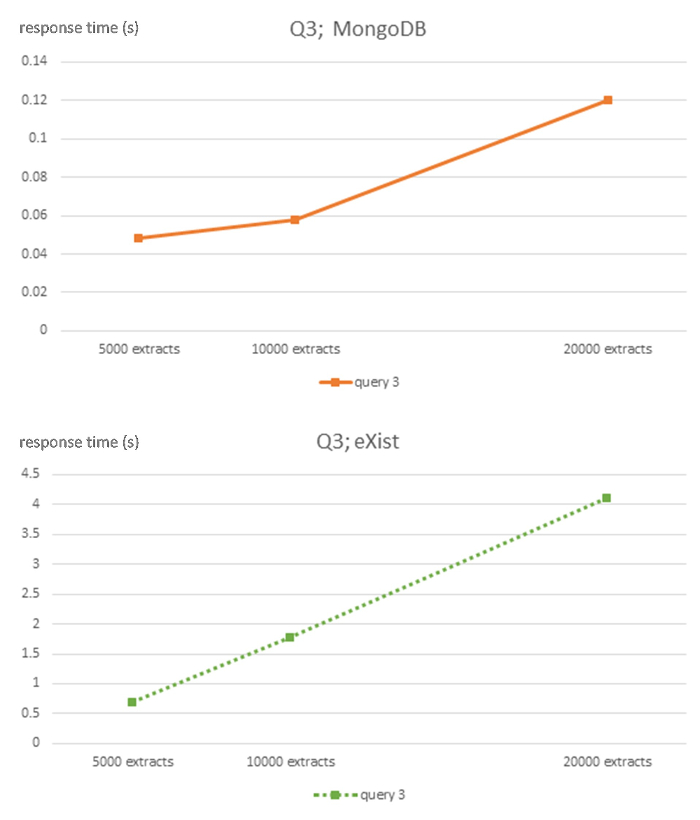
Figure 5: Algorithmic complexity of eXist and MongoDB DBMS for query Q3. This figure has been modified from7 using Creative Commons license (http://creativecommons.org/licenses/ by/4.0/ ) and shows response times in seconds for 5,000, 10,000 and 20,000-sized EHR extracts databases for each DBMS and query Q3. Please click here to view a larger version of this figure.
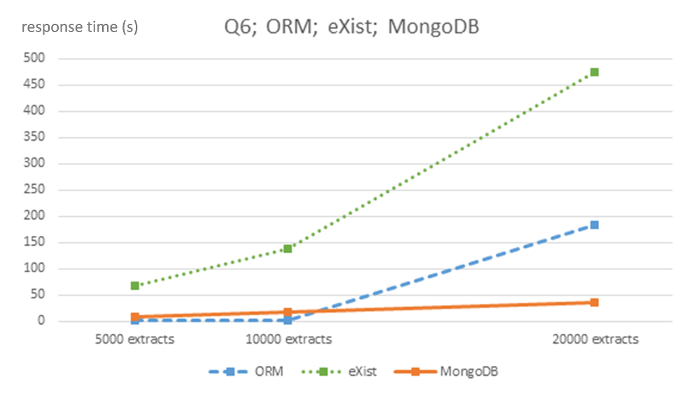
Figure 6: Algorithmic complexity of ORM MySQL, eXist and MongoDB DBMS for query Q6. This figure has been modified from7 using Creative Commons license (http://creativecommons.org/licenses/ by/4.0/) and shows response times in seconds for 5,000, 10,000 and 20,000-sized EHR extracts databases for each DBMS and query Q6. Please click here to view a larger version of this figure.
| Query | |
| Q1 | Find all problems of a single patient |
| Q2 | Find all problems of all patients |
| Q3 | Find initial date, resolution date and severity |
| of a single problem of a single patient | |
| Q4 | Find initial date, resolution date and severity |
| of all problems problem of a single patient | |
| Q5 | Find initial date, resolution date and severity |
| of all problems problem of all patients | |
| Q6 | Find all patients with problem 'pharyngitis', |
| initial date >= '16/10/2007', resolution date | |
| <= '06/05/2008' and severity 'high' |
Table 1: The six queries performed on the relational and NoSQL databases containing standardized EHR extracts about problems of patients. This table has been modified from7 using Creative Commons license (http://creativecommons.org/ licenses/by/4.0/) and shows the six complexity-growing queries performed on the three size-growing databases for each DBMS expressed in natural language.
| ORM/MySQL | 5000 docs | 10,000 docs | 20,000 docs |
| Q1 (s) | 25.0474 | 32.6868 | 170.7342 |
| Q2 (s) | 0.0158 | 0.0147 | 0.0222 |
| Q3 (s) | 3.3849 | 6.4225 | 207.2348 |
| Q4 (s) | 33.5457 | 114.6607 | 115.4169 |
| Q5 (s) | 9.6393 | 74.3767 | 29.0993 |
| Q6 (s) | 1.4382 | 2.4844 | 183.4979 |
| Database size | 4.6GB | 9.4GB | 19.4GB |
| Total extracts | 5000 | 10,000 | 20,000 |
Table 2: Average response times in seconds of the six queries on doubling-size databases of the ORM MySQL relational DBMS. This table shows six response times for each query for the three doubling-sized databases using the ORM MySQL relational DBMS and the in-memory size of the three databases.
| MongoDB | 5000 docs | 10,000 docs | 20,000 docs | slope (*10exp(-6)) |
| Q1 (s) | 0.046 | 0.057 | 0.1221 | 5.07 |
| Q2 (s) | 34.5181 | 68.6945 | 136.2329 | 6,780.99 |
| Q3 (s) | 0.048 | 0.058 | 0.1201 | 4.81 |
| Q4 (s) | 0.052 | 0.061 | o.1241 | 4.81 |
| Q5 (s) | 38.0202 | 75.4376 | 149.933 | 7460.85 |
| Q6 (s) | 9.5153 | 18.5566 | 36.7805 | 1,817.68 |
| Database size | 1.95GB | 3.95GB | 7.95GB | |
| Total extracts | 5000 | 10,000 | 20,000 |
Table 3: Average response times in seconds of the six queries on doubling-size databases of the MongoDB NoSQL DBMS. This table has been modified from7 using Creative Commons license (http://creativecommons.org/ licenses/by/4.0/) and shows the six response times of each query for the three doubling-sized databases using the NoSQL MongoDB DBMS and the in-memory size of the three databases. The linear slope of each query is also shown.
| eXist | 5000 docs | 10,000 docs | 20,000 docs | slope (*10exp(-6)) |
| Q1 (s) | 0.6608 | 3.7834 | 7.3022 | 442.76 |
| Q2 (s) | 60.7761 | 129.3645 | 287.362 | 15,105.73 |
| Q3 (s) | 0.6976 | 1.771 | 4.1172 | 227.96 |
| Q4 (s) | 0.6445 | 3.7604 | 7.3216 | 445.17 |
| Q5 (s) | 145.3373 | 291.2502 | 597.7216 | 30,158.93 |
| Q6 (s) | 68.3798 | 138.9987 | 475.2663 | 27,125.82 |
| Database size | 1.25GB | 2.54GB | 5.12GB | |
| Total extracts | 5000 | 10,000 | 20,000 |
Table 4: Average response times in seconds of the six queries on doubling-size databases of the eXist NoSQL DBMS. This table has been modified from7 using Creative Commons license (http://creativecommons.org/ licenses/by/4.0/) and shows the six response times of each query for the three doubling-sized databases using the NoSQL eXist DBMS and the in-memory size of the three databases. The linear slope of each query is also shown.
| ARM paper | ARM (s) | Node+Path (s) | |
| Q1 | Query 2.1 | 0.191 | 24.866 |
| Q3 | Query 3.1 | 0.27 | 294.774 |
| Database size | 2.90GB | 43.87GB | |
| Total extracts | 29,743 | 29,743 |
Table 5: Average response times in seconds of queries similar to Q1 and Q3 of the improved relational systems presented in10. This table has been modified from7 using Creative Commons license (http://creativecommons.org/ licenses/by/4.0/) and shows the two most-similar queries to Q1 and Q3 presented in10 corresponding to two improved relational database systems and their response times. The two database sizes are also shown.
| ORM/MySQL | Throughput | Response time |
| Q1 (s) | 4,711.60 | 0.0793 |
| Q3 (s) | 4,711.60 | 0.1558 |
| Q4 (s) | 4,711.60 | 0.9674 |
Table 6: Average throughput and response time in seconds of queries Q1, Q3 and Q4 of ORM MySQL relational DBMS in concurrent execution. This table has been modified from7 using Creative Commons license (http://creativecommons.org/ licenses/by/4.0/) and shows the highest average throughput of the three single-patient queries and their average response times in the concurrent execution experiment using the ORM MySQL relational system.
| MongoDB | Throughput | Response time |
| Q1 (s) | 178,672.60 | 0.003 |
| Q3 (s) | 178,672.60 | 0.0026 |
| Q4 (s) | 178,672.60 | 0.0034 |
Table 7: Average throughput and response time in seconds of queries Q1, Q3 and Q4 of MongoDB NoSQL DBMS in concurrent execution. This table has been modified from7 using Creative Commons license (http://creativecommons.org/ licenses/by/4.0/) and shows the highest average throughput of the three single-patient queries and their average response times in the concurrent execution experiment using the MongoDB NoSQL system.
Supplementary Figure 1: The screenshot shows the software screen to connect to the MySQL server. Please click here to download this figure.
Supplementary Figure 2: The screenshot shows the SQL interface to the MySQL server where the first SQL query has been written. Please click here to download this figure.
Supplementary Figure 3: The MongoDB 2.6 localhost server is launched using a DOS system window by executing the server mongod. Please click here to download this figure.
Supplementary Figure 4: The screenshot shows the query written in the textboxes of the Query Builder as shown in steps 5.7.1 through 5.7.4. The screenshot illustrates step 5.7.3. Please click here to download this figure.
Supplementary Figure 5:The screenshot shows the step 5.7.6. Please click here to download this figure.
Supplementary Figure 6: The screenshot illustrates the writing of the XPath query in theupper part of the dialog. Please click here to download this figure.
