1. Introduction
Multivariate pattern analysis (MVPA) is an increasingly popular method of analyzing functional magnetic resonance imaging (fMRI) data1-4. Typically, the method is used to identify a subject’s perceptual experience from neural activity in certain regions of the brain. For instance, it has been employed to predict the orientation of visual gratings a subject perceives from activity in early visual cortices5 or, analogously, the content of speech from activity in early auditory cortices6. In this video article, we describe a novel application of MVPA which adds an extra twist to this basic, intra-modal paradigm. In this approach, perceptual stimuli are predicted not within, but across sensory systems.
2. Multivariate Pattern Analysis
Although the MVPA method by now is well established within the neuroimaging realm, we will start by pointing out the key differences between MVPA and conventional, univariate fMRI analysis. To this end, consider the following example of how the two methods go about examining neural activity in the visual cortex during a simple visual task (Video Clip 1):
- A subject is presented with two different visual stimuli, for instance, an image of an orange and an image of an apple.
- Both stimuli induce a specific pattern of neural activity in the primary visual cortex, symbolized here by the activation levels of six hypothetic voxels. (Of course, activity patterns induced by a single presentation of the orange or apple images in reality would be very noisy; consider the illustrated patterns as averages resulting from a large number of trials.)
- In conventional fMRI analysis, there are essentially two ways in which these patterns can be analyzed. First, one can focus on the average level of activity across the entire region of interest.
- In the example given, the difference in average activity levels is not significant, so that the patterns corresponding to the two stimuli cannot be distinguished from this point of view.
- Another way to analyze the two patterns is to establish a subtraction contrast between them: for each voxel, the activation level during the “apple” condition is subtracted from the activation level during the “orange” condition. The resulting difference can then be visualized for each voxel on a whole-brain contrast image.
- Again, however, these differences may be small and may reach the required statistical criterion only for very few voxels.
- This is where the decisive advantage of MVPA comes into play: its superior power derives from the fact that, unlike univariate analysis methods, it considers the activation levels of all voxels simultaneously and thus is able to detect patterns within them. While, as mentioned, only few of the activation differences may be significant when considered in isolation, the two patterns, when considered in their entirety, may indeed by statistically different.
There is a second major difference between conventional fMRI analysis and MVPA (Video Clip 2). The former method typically attempts to demonstrate a statistical dependency between certain sensory stimuli and certain brain activity patterns in a “forward manner”; in other words, it asks question of the type: “Will two different visual stimuli, e.g. the picture of a face and the picture of a house, lead to different activity levels in a specific region of interest, e.g. the fusiform face area?” By contrast, the success of MVPA is typically expressed in terms of “reverse inference” or “decoding”; the typical question is of the type: “Based on the pattern of neural activity in a specific region of interest (e.g. the primary visual cortex), can one predict whether a subject perceives stimulus A, e.g. an orange, or stimulus B, e.g. an apple?” Note, however, that the direction in which the correlation between the perceptual stimuli and brain activity is mapped does not matter from a statistical point of view: it is equivalent to say that two stimuli lead to distinct activity patterns in a given brain region and to say that the activity pattern in that brain region permits prediction of the inducing stimulus11. In other words, the sensitivity of MVPA is superior to that of univariate analyses because it considers several voxels simultaneously, and not because it proceeds in an inverse direction.
The following steps illustrate how a typical MVPA paradigm would address the question of whether seeing an apple induces a different pattern of neural activity in primary visual cortex than seeing an orange (Video Clip 3):
- fMRI data are acquired while a subject sees large number of apple and orange stimuli.
- The acquired data are divided into a training data set and a testing data set. Unlike in the present example, the training data set is often chosen to be larger than the testing data set, as the performance of the classifier can be expected to increase with the number of training trials.
- The data from the training set are entered into a pattern classifier. Using one of several possible mathematical algorithms, the classifier attempts to detect features in the neural patterns that distinguish the two stimulus types from one another. A type of classifier commonly used (also in our own previous studies) are so-called support vector machines; for further detail, the reader is referred to the reviews mentioned in the introduction.
- After the classifier has been trained on the training trials, it is provided with the testing data. The individual trials from the testing data set are unlabeled; in other words, the classifier does not “know” whether a pattern comes from an “apple” or an “orange” trial.
- Based on the consistencies it was able to detect in the training data set, the classifier attributes the most likely label to each of the testing trials.
- For each pattern, the classifier “guess” can be compared with the correct stimulus label.
- If the classifier was unable to detect any consistent differences between the patterns induced by the two stimuli, its performance should be at chance level; for the two-way discrimination given in the example, this would correspond to 50% correct labels. A prediction performance significantly above this value indicates that there are indeed consistent differences between the two types of stimuli.
Note that it is crucial that the training and testing data sets be independent from one another. Only if this is the case can any conclusions be drawn as to the generalizability of the patterns derived from the training set. MVPA studies often assess classifier performance using a cross-validation paradigm (Video Clip 4). Assume that an MVPA experiment consists of eight functional runs. In the first cross-validation step, a classifier is trained on the data from runs 1 through 7 and tested on the data from run 8. In the second step, the classifier is then trained on runs 1 through 6 as well as run 8, and subsequently tested on run 7. Following this schema, eight cross-validation steps are carried out, with each run serving as test run exactly once. Overall classifier performance is calculated as the average of the performances on the individual cross-validation steps. While this procedure guarantees independent training and testing data sets on each step, it also maximizes the overall number of testing trials, which can be of advantage when assessing the statistical significance of the classifier’s performance.
There are freely available software packages on the internet to perform MVPA; two examples are PyMVPA12 (based on Python; http://www.pymvpa.org) and the toolbox offered by the Princeton Neuroscience Institute (based on Matlab; http://code.google.com/p/princeton-mvpa-toolbox/).
3. Cross-Modal MVPA and the Framework of Convergence-Divergence Zones
As mentioned in the introduction, experimental paradigms like the one just described have been used successfully to predict perceptual stimuli from neural activity in corresponding sensory cortices, in other words, visual stimuli based on activity in visual cortices and auditory stimuli based on activity in auditory cortices. Here, we present an extension of this basic concept. Specifically, we hypothesized that it should be possible to predict perceptual stimuli not only within, but across modalities. Sensory perception is intricately linked to the recall of memories; for example, a visual stimulus that has a strong auditory implication, such as the sight of a glass vase shattering on the ground, will automatically trigger in our “mind’s ear” images that share similarities with the auditory images we experienced on previous encounters with breaking glass. According to a framework introduced by Damasio more than two decades ago9,10, the memory association between the sight of the vase and the corresponding sound images is stored in so-called convergence-divergence zones (CDZs; Video Clip 5). CDZs are neuron ensembles in the association cortices which receive converging bottom-up projections from various early cortical areas (via several hierarchical levels) and which, in turn, send back divergent top-down projections to the same cortical sites. Due to the convergent bottom-up projections, CDZs can be activated by perceptual representations in multiple modalities – for instance, both by the sight and the sound of a shattering vase; due to the divergent top-down projections, they can then promote the reconstruction of associated images by signaling back to the early cortices of additional modalities. Damasio emphasized the latter point: activating CDZs in association cortices would not be sufficient for the conscious recall of an image from memory; only once CDZs would reconstruct explicit neural representations in early sensory cortices would the image be consciously experienced. Thus, the framework predicts a specific sequence of neural processing in response to a (purely) visual stimulus that implies sound (Video Clip 6):
- The stimulus first induces a specific pattern of neural activity (red rectangles) in the early visual cortices.
- Via convergent bottom-up projections, the neurons in early visual cortices project forward to a first level of CDZs (CDZ1s). The convergent pattern of connectivity permits the CDZ1s to detect certain patterns of activity in the early visual cortices. Depending on the exact pattern, a CDZ may or may not become activated. CDZs thus act as feature extractors. In this example, two CDZ1s become activated (as indicated by the red color), while the third is not triggered by the specific activity pattern in the corresponding sector of the early visual cortices.
- CDZ1s send convergent bottom-up projections to CDZ2s; therefore, just as CDZ1s detected certain patterns of activity in the early visual cortices, CDZ2s are able to detect patterns of activity among CDZ1s. Several CDZ2s may become activated by the specific configuration of activated CDZ1s; for reasons of simplicity, only a single CDZ2 is depicted here. In the example, the activity pattern among CDZ1s is adequate to activate this CDZ2.
- Notably, CDZ1s do not only project forward to CDZ2s but also back to the early cortices (blue arrows). These top-down signals may complete the (possibly noisy) activity pattern initially induced by the stimulus (blue rectangle). Generally, red color denotes bottom-up activations, while blue color represents top-down activations.
- Via several additional levels of CDZs, the CDZ2s project forward to CDZns in higher-order association cortices (dashed arrow). One or several CDZns may respond to the specific visual stimulus in question (only a single one is depicted).
- Again, it should be noted that the CDZ2s also signal backward to CDZ1s which, in turn, may further modify the pattern originally induced in the early visual cortices.
- The CDZns signal back to the CDZ2s of all modalities. In the visual cortices, this may lead to the completion of activity patterns in lower-level CDZs. In the auditory cortices, a neural pattern will be constructed – first at the level of CDZ2s and CDZ1s, ultimately in the early auditory cortices – which permits the conscious experience of an auditory image associated with the visually presented stimulus. Note that there is also top-down signaling to the somatosensory modality, although to lesser extent than for the auditory modality. This reflects the fact that almost any visual stimulus has some tactile association to it. As the visual stimulus in the current example is assumed to specifically imply sound, however, top-down signaling to the auditory cortices is more extensive.
Based on the proposed sequence of neural processing, the framework makes a specific prediction: visual stimuli containing objects and events that strongly imply sound should evoke neural activity in early auditory cortices. Moreover, the auditory activity patterns should be stimulus-specific; in other words, a video clip of a shattering vase should induce a different pattern than a clip of a howling dog. If this prediction were correct, then we should indeed be able to perform MVPA cross-modally: for instance, we should be able to predict, based exclusively on the neural activity fingerprint in early auditory cortices, whether a person is seeing a shattering vase or a howling dog (Video Clip 7). Naturally, analogous paradigms invoking information transfer among other sensory modalities should also be successful. For instance, if the video clips shown to a subject implied touch rather than sound, we should be able to predict those clips from the activity patterns they elicit in early somatosensory cortex.
4. Stimuli
The general paradigm of an MVPA study was described in Section 2. Our approach is different from previous studies in that it attempts to perform MVPA across sensory systems and therefore uses stimuli that are specifically designed to have implications in a sensory modality other than the one in which they are presented. In one previous study, for instance, we recorded neural activity from primary somatosensory cortex while subjects watched 5-second video clips of everyday objects being manipulated by human hands8 (Video Clip 8 and Video Clip 9). In another study, we investigated neural activity in early auditory cortices while subjects viewed video clips that depicted objects and events that strongly implied sound7 (Video Clip 10 and Video Clip 11). However, according to the CDZ framework, sensory stimuli of all modalities can potentially be employed in this general paradigm, as long as they have implications in additional modalities.
5. Regions of Interest
Generally, the regions of interest for a neuroimaging study can be determined either functionally or anatomically. We believe that in the experimental paradigm we describe here, anatomical localizers are more suitable for two reasons. First, it is not trivial to functionally define the primary or early cortices of a given sensory modality (with the possible exception of the primary visual cortex), as processing of perceptual stimuli presented to the subject in that modality typically will not be limited to these areas. For instance, it would be difficult to define the primary somatosensory cortex by applying touch to a subject’s hands, as the activity induced by this procedure would, in all likelihood, spread to somatosensory association cortices as well. Second, a functional localizer may not label all the voxels that could potentially contribute to the classifier’s performance: it has been shown that areas that do not show net activation in response to sensory stimuli in the classical sense (i.e., regions that do not appear on a contrast image [stimulation vs. rest]) can contain information about the stimuli nonetheless13,14. For these two reasons, we advocate the use of anatomically defined regions of interest whenever macroscopic landmarks allow for this; for example, the gross anatomy of the postcentral gyrus represents a reasonable approximation of the primary somatosensory cortex, and we used this to define the region of interest in our somatosensory study8 (Figure 1).
6. Subjects
The subject samples in MVPA studies tend to be smaller than in conventional fMRI studies, as the analysis can be performed at the single-subject level. Of course, this does not prevent the experimenter from subsequently analyzing the results of the individual subjects at the group level as well. In the two studies mentioned earlier, for example, we conducted t-tests on the individual subject results in order to assess their significance at the group level. Each study involved eight subjects; although this must be considered a very small subject sample for parametric testing, we did find many of the discriminations we assessed to be significant (see below).
7. Representative Results:
As mentioned, in two previous studies we aimed to predict sound-implying video clips based on neural activity in early auditory cortices7 (see Figure 2 for the mask used in this study) and touch-implying video clips based on activity in primary somatosensory cortices8. This attempt was successful: in both studies, an MVPA classifier performed above the chance level of 50% for all possible two-way discriminations between stimulus pairs (n = 36 in the auditory study, given there were 9 different stimuli; n = 10 for the somatosensory study, given there were 5 different stimuli). In the auditory study, 26 out of the 36 discriminations reached statistical significance; in the somatosensory study, this was the case for 8 out of the 10 discriminations (two-tailed t-tests, n = 8 in both studies; Figure 3).
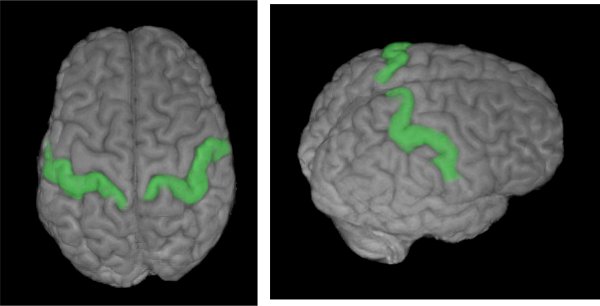
Figure 1. Extent of the anatomically defined mask of primary somatosensory cortex, as used in Meyer et al., 2011. A classifier algorithm was able to predict touch-implying video clips from brain activity patterns restricted to the demarcated region. Reproduced with permission from Oxford University Press.
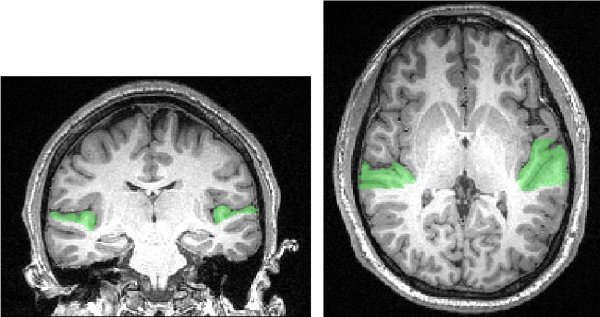
Figure 2. Extent of the anatomically defined mask of early auditory cortices, as used in Meyer et al., 2010. A classifier algorithm was able to predict (silent) sound-implying video clips from brain activity patterns restricted to the demarcated region. Reproduced with permission from Nature Publishing Group.
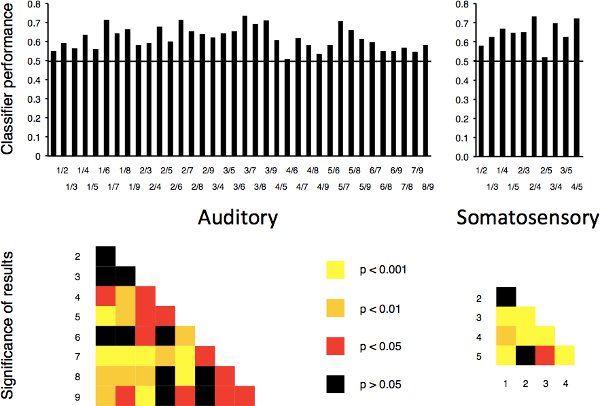
Figure 3. Summary of the results of our previous cross-modal MVPA studies. A classifier was used to predict visual stimuli that implied either sound or touch from activity in the early auditory or primary somatosensory cortices, respectively. Top panels: in both studies, prediction performance was above the chance level of 0.5 for all two-way discriminations between pairs of stimuli. Bottom panels: in the auditory study, classifier performance reached statistical significance for 26 of the 36 discriminations; in the somatosensory study, this was the case for 8 of the 10 discriminations. Reproduced with permission from Nature Publishing Group and Oxford University Press.
