1. Identification of a Natural Product with Antibiotic Property
- Cultivate a microorganism under different conditions (e.g. time, temperature, pH, media) following the "OSMAC (one strain-many compounds) approach"13. Select one medium in which the production of a compound is observed.
- Cultivate Streptomyces diastatochromogenes Tü6028 under the following conditions
- Grow Streptomyces diastatochromogenes Tü6026 strain on MS plates (soy flour 20 g, D-mannitol 20 g, MgCl2 10 mM, agar 1.5%, tap water 1 L). Inoculate a small loop of the spores of this strain into 20 mL liquid TSB medium (tryptic soy broth 30 g, tap water 1 L, pH 7.2; preculture medium) in an Erlenmeyer flask with a spiral. Shake the flask on a rotary shaker (28 °C, 180 rpm, 2 days).
- Inoculate main culture in 100 mL HA medium (glucose 4 g, yeast extract 4 g, malt extract 10 g, tap water 1 L, pH 7.2) with 2 mL of the preculture. Culture the strain at 28 °C for 6 days on a rotary shaker at 180 rpm.
- Preparation of the crude extract
- Harvest cells by centrifugation (10 min, 3,000 x g).
- For next steps handle organic solvents under a fume hood.
- For compound extraction from the mycelium, resuspend cells in a twofold volume of acetone and shake in a tube for 30 min, 180 rpm. Filter the liquid through commercial filter paper and evaporate acetone by rotary evaporator at 40 °C and 550 bar. Dissolve the extract in 20 mL water:ethyl acetate (1:1) and shake it in a separating funnel for 30 min at 180 rpm.
- For compound extraction from the culture medium, adjust the culture broth to pH 4.0 by the addition of 1 M HCl. Add 100 mL ethyl acetate and shake it in a separating funnel for 30 min, 180 rpm.
- Collect ethyl acetate phase and evaporate by rotary evaporation at 40 °C and 240 bar.
- Analysis of the crude extract by HPLC
- Dissolve the extracts in 1 mL MeOH, filter them through a 0.45 µm pore size filter and run high-performance liquid chromatography (HPLC)14.
- In the case of polyketomycin, equip the HPLC system with a C18 precolumn (4.6 x 20 mm2) and a C18 column (4.6 x 100 mm2). Use a linear gradient of acetonitrile + 0.5% acetic acid ranging from 20% to 95% in H2O + 0.5% acetic acid (flow rate: 0.5 mL min-1).
NOTE: Polyketomycin has a retention time of 25.9 min (see Figure 1A). The UV/vis spectrum has maxima at 242 nm, 282 nm, 446 nm and minima at 262 nm and 359 nm (see Figure 1B). In the negative modus a mass of 863.2 [M-H]– is detectable (see Figure 1C).
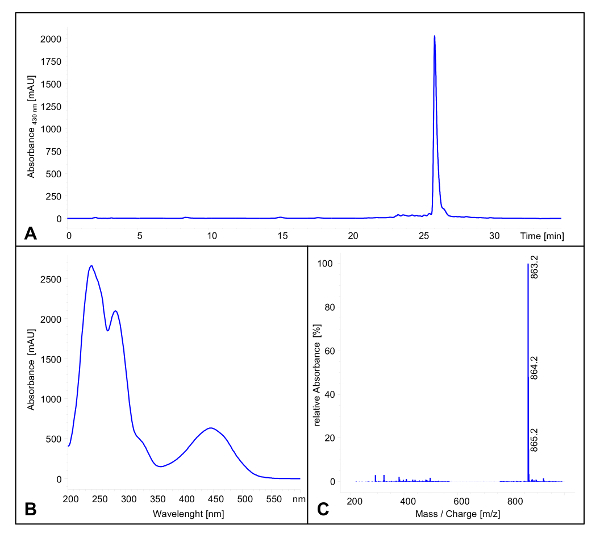
Figure 1: LC/MS Analysis of Polyketomycin. (A) HPLC chromatogram (λ = 430 nm) of the crude extract after cultivation of Streptomyces diastatochromogenes Tü6028 for 6 days. Polyketomycin has a retention time of 25.9 min (B) UV/vis spectra of Polyketomycin. (C) Mass spectra of Polyketomycin in the negative modus. Main peak with m/z 863.2 [M-H]–.Please click here to view a larger version of this figure.
- Identification of the antibiotic activity using disc diffusion assay
- Inoculate test strains like Gram-positive bacteria Bacillus subtilis (in LB medium; LB 20 g, tap water 1 L, pH 7.4) and other Streptomyces strains (in TSB medium; tryptic soy broth 30 g, tap water 1 L, pH 7.2), Gram-negative bacteria Escherichia coli (in LB medium) and fungal strains (in media such as YPD medium; yeast extract 10 g, peptone 20 g, glucose 20 g, tap water 1 L, pH 7.4). Take 100 µL of test strain preculture and spread them onto respective agar plates.
- Dissolve the crude extract or purified compound in 500 µL of methanol (alternatively water or DMSO) and pipette 20-50 µL onto sterile paper discs. Dry paper discs for 30 min under the work bench and put them onto the plates with test cultures. Prepare a negative control (solvent) and a positive control (antibiotic, e.g. apramycin [1 mg]).
- Incubate the plates under adequate conditions until the test strains are visibly grown and determine inhibition zone, if apparent. Incubate E. coli and Bacillus sp. at 37 °C for 16 h, Streptomyces sp. at 28 °C for 2-4 days, fungal strain (mainly dependent on exact test strain) at 30 °C for 2 days).
2. Large Scale Extraction, Purification and Structure Elucidation of the Compound
- Cultivate S. diastatochromogenes in 5 L HA medium (glucose 4 g, yeast extract 4 g, malt extract 10 g, tap water 1 L, pH 7.2). Inoculate 2 mL of the preculture in 30 x 500 mL Erlenmeyer flasks containing 150 mL HA medium. Incubate the strain at 28 °C for 6 days on a rotary shaker at 180 rpm.
- Harvest cells by centrifugation (10 min, 15,000 x g, RT) and extract compounds using ethyl acetate (see section 1.3).
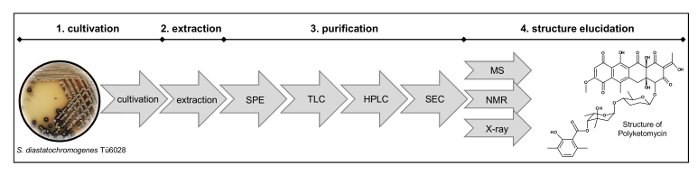
Figure 2: Workflow for Structure Elucidation. The process comprises (1) cultivation of the strain, (2) extraction, (3) purification by solid phase extraction (SPE), thin layer chromatography (TLC), preparative high-performance liquid chromatography (HPLC), size exclusion chromatography (SEC) and (4) structure elucidation by mass analysis (MS), nuclear magnetic resonance (NMR) and X-ray measurements. Please click here to view a larger version of this figure.
- Purification of Polyketomycin
NOTE: The process of purification and structure elucidation is shown in Figure 2.- Fractionate crude extract by a C18 solid phase extraction (SPE) column using a 10%-stepwise MeOH gradient ranging from 30% to 100% MeOH in H2O, 100 mL for each condition.
- Purify the compound-containing fraction further by preparative thin-layer chromatography (TLC)15 using CH2Cl2/MeOH (7:1) as elution system.
- Purify the compound by preparative HPLC16. Equip the HPLC system with a C18 precolumn (5 µm; 9.4 x 20 mm) and a main column (5 µm; 9.4 x 150 mm). Use a gradient of acetonitrile + 0.5% acetic acid ranging from 20% to 95% in H2O + 0.5% acetic acid (flow rate: 2.0 mL/min).
- To remove solvents and other small impurities, perform a last purification step by size exclusion chromatography using a column in MeOH17. Collect the final pure compound and evaporate MeOH by rotary evaporation at 40 °C and 240 bar.
- Structure elucidation
- Dissolve the pure compound (more than 2 mg) in 600-700 µL (dependent on the machine) of DMSO-d6, record 1D NMR (1H, 13C) and 2D NMR (HSQC, HMBC,1H-1H COSY) spectra on a NMR spectrometer18. Express chemical shifts in δ values (ppm) by using DMSO-d6.
- Record a high-resolution mass spectrum (HRESI-MS)19 of polyketomycin using a high-resolution mass spectrometer.
- Elucidate the structure by interpretation of the results of NMR and MS data analysis10.
3. Propose Biosynthetic Model of the New Isolated Compound
- Analyze the structure of the isolated compound and predict enzymes, which might be involved in its biosynthesis. Assign them to polyketide (type I, II or III), non-ribosomal peptide synthesis, lantipeptide, terpenoid, or sugar metabolism pathway8.
- Example polyketomycin
- Subdivide the structure into obvious single moieties: tetracyclic moiety, two monosaccharides and the dimethyl salicylic acid.
- Find out, where the moieties might be derived from: The tetracyclic moiety might be derived from a polyketide synthase type II and the dimethyl salicylic acid moiety might be derived by an iterative polyketide synthase type I. The two sugar moieties, which are 6-deoxysugars, might be synthesized from glucose involving a TDP-glucose-4,6-dehydratase during biosynthesis and attached probably by two glycosyltransferases (see Figure 3)8.
- Predict putative genes in the cluster. Think of enzymes which are involved in the synthesis of the single moieties, in connecting the units, as well as in modifying and tailoring the molecule. The biosynthetic gene cluster of Polyketomycin most probably contains genes encoding a polyketide synthase type II (therefore minimum an ACP, KSα und KSβ for connecting extender units), an iterative polyketide synthase type I (at least ACP, AT, KS), a TDP-glucose-4,6-dehydratase (necessary for step: glucose → deoxyglucose) and two glycosyltransferases (attaching two sugar monomers to the aglycone)8.
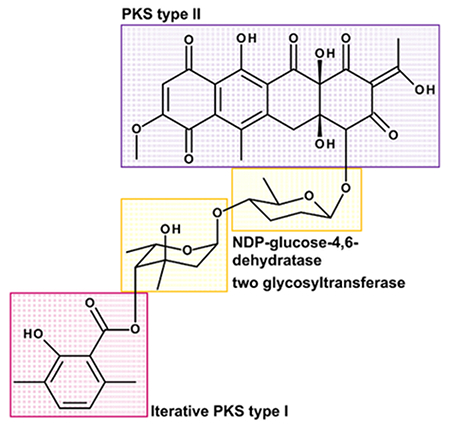
Figure 3: Structure of Polyketomycin Divided into Single Building Blocks. Polyketomycin is composed of a tetracyclic decaketid (PKS type II) and a dimethyl salicylic acid (iterative PKS type I), linked by the two deoxysugar moieties β-D-amicetose and α-L-axenose (NDP-glucose-4,6-dehydratase and two glycosyltransferase required). Please click here to view a larger version of this figure.
4. Genome Sequencing/Mining
- Next generation sequencing
- Sequence the genomic DNA by next generation sequencing technologies like Illumina, 454 pyrosequencing or SOLiD20. Align single reads to a reference sequence or assemble de novo.
NOTE: The genome of S. diastatochromogenes Tü6028 was sequenced at the Center for Biotechnology (CeBiTec) at the University of Bielefeld. All reads were assembled to a draft genome of 7.9 Mb.
- Sequence the genomic DNA by next generation sequencing technologies like Illumina, 454 pyrosequencing or SOLiD20. Align single reads to a reference sequence or assemble de novo.
- Genome mining
- Search for open reading frames (ORFs) by the usage of for example NCBI Prokaryotic Genome Annotation Pipeline21,22, RAST (rapid annotation using subsystem technology)23,24,25, Prokka (rapid prokaryotic genome annotation)26 or GenDB27. These programs also propose their functions. The analysis of the S. diastatochromogenes Tü6028 draft genome sequence led to the identification of more than 7,000 ORFs.
- Run specific BLAST (Basic Local Alignment Search Tool) analysis to get more information like alignments with other similar genes and catalytic domains28,29,30.
- For the identification of the secondary metabolite gene cluster run programs like antiSMASH31,32,33, NaPDoS34 and NRPSpredictor35,36. In the draft genome of Streptomyces diastatochromogenes antiSMASH31,32,33 identified 22 gene clusters.
- Analyze the putative gene clusters for their enzymatic pathway(s) (polyketide synthase (type I, II or III), non-ribosomal peptide synthetase, lanthipeptide, terpenoid, sugar metabolism …). Search for cluster(s) containing genes which might be involved in the synthesis of the compound (see section 3). In S. diastatochromogenes annotated cluster 2 contains polyketide synthase type II genes, three polyketide synthase type I genes, a TDP-glucose-4,6-dehydratase gene and two glycosyltransferase genes (see Figure 4).
- Focus on single genes within the cluster. For PKS type I and NRPS the specificity of acyltransferases and adenylation domains, and thus the incorporation of single extender units, may be predicted. Also compare the order of the incorporated extender unit with the molecule. antiSMASH31,32,33 also shows similar clusters of already known compounds, with a link to MIBiG database37.
- Compare the structure of the compound with these other compounds and check for similarities.

Figure 4: antiSMASH Output of Polyketomycin Biosynthetic Gene Cluster and Overview of Other Clusters in S. diastatochromogenes Tü6028. (A) Overview of predicted biosynthetic gene clusters in the genome of S. diastatochromogenes Tü6028; (B) Cluster 2 Polyketomycin biosynthetic gene cluster with targeted genes. Please click here to view a larger version of this figure.
5. Verification of the Biosynthetic Gene Cluster
- Search for a gene with obvious and important (essential) functions for biosynthesis of the compound. For verification of the polyketomycin gene cluster the gene pokPI, coding for the ketosynthase α from the PKS type II, was selected and inactivated by an out of frame-deletion (see Figure 5B). Alternatively, interrupt the gene by cloning an internal fragment (see Figure 5C).
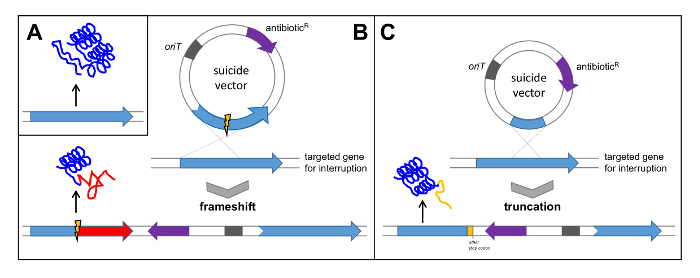
Figure 5: Verification of a Gene Cluster by Single Crossover. (A) Native gene leads to the translation of a functional protein; (B) Cloning of the gene with internal deletion into a suicide vector leads to a single crossover resulting in a frame shift in the targeted gene and subsequent translation of non-functional protein; (C) Cloning of an internal fragment of the gene into a suicide vector leads to a truncation of the gene and subsequent translation of a non-functional protein. oriT: origin of transfer; antibioticR: antibiotic resistance. Please click here to view a larger version of this figure.
- Cloning of the single-crossover construct
- Amplify a fragment containing pokPI by PCR38 with primers pokPI_for and pokPI_rev.
- Clone PCR product into suicide vector pKC113239 (apramycinR [50 mg/mL]). The suicide vector is not able to replicate in the Streptomyces strain and thus has to integrate into the targeted gene by homologous recombination to provide apramycin-resistance. Transfer the vector into E. coli cloning host by heat shock transformation40.
- Isolate the vector by alkaline lysis41.
- Digest the vector DNA with a single cutter restriction enzyme that cuts within the fragment. The pokPI gene was digested with enzyme KpnI.
- Treat digested vector DNA with large DNA polymerase I (klenow) fragment, which has 5'→3' polymerase activity and 3'→5' exonuclease-activity. Blunting of the sticky ends and subsequent religation leads to loss of four bases. Check for loss of these bases by the steps transformation into E. coli XL1 Blue, picking single colonies, isolating their plasmid DNA,41 and analyzing further by restriction digestion and sequencing.
- Conjugation of the single-crossover construct into Streptomyces
- Transfer the suicide vector containing the pokPI gene (pKC1132_pokPIdel) with deletion into E. coli ET12567 pUZ800242 (kanamycinR) by heat shock transformation40. Incubate the cells in 100 mL LB media (kanamycin 50 µg mL-1, apramycin 50 µg mL-1) overnight at 37 °C. Harvest cells by centrifugation (3,000 x g, 10 min, 4 °C) and wash cells twice by resuspending in 50 mL LB media. Finally, resuspend cells in 2 x 500 µL of LB media.
- Mix 500 µL E. coli pUZ8002 pKC1132_pokPIdel with 500 µL Streptomyces diastatochromogenes culture (alternatively use spores). Spread the mixture on MS plates (soy flour 20 g, D-mannitol 20 g, MgCl2 10 mM, agar 1.5%, tap water 1 L). Incubate the plates for 20 h at 28 °C.
- Overlay each plate with apramycin (1.25 mg) and fosfomycin (5 mg) dissolved in 1 mL of water and let them dry. Incubate the plates for several days at 28 °C until exconjugants are visible.
- Check single-crossover mutants
- Inoculate single exconjugants in 20 mL TSB medium (apramycin 50 mg mL-1) and incubate them at 28 °C for three days and 180 rpm.
- Isolate genomic DNA43 and check interruption of the pokPI gene by PCR.
- Inoculate single clones with verified gene interruption and Streptomyces wildtype strain in 100 mL HA medium and incubate them for 6 days at 28 °C and 180 rpm. Extract the crude extract (see section 1.3). Check compound production by HPLC-MS analysis (see section 1.4). The corresponding peak in the HPLC chromatogram and the mass of the compound should not be detectable any more (see Figure 6).
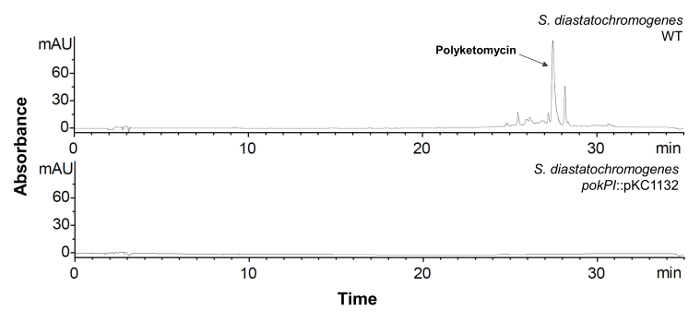
Figure 6: HPLC Analysis of S. diastatochromogenes with Inactivated pokPI Gene. HPLC chromatogram (λ = 430 nm) of crude extract of S. diastatochromogenes WT (top) and mutant strain with interrupted pokPI-Gen (below). The mutant strain does not produce polyketomycin anymore. Please click here to view a larger version of this figure.
In this overview we describe the single steps from identification of an antibiotic leading to its biosynthetic gene cluster. Many years ago we cloned a cosmid library, packaged them into phages, transduced E. coli host cells, and had to screen thousands of colonies to identify the clones having overlapping regions of polyketomycin cluster. Sequencing of the cosmids was also a difficult and expensive process12.
In order to conduct further studies on the strain we sequenced the whole genome of Streptomyces diastatochromogenes Tü6028. With the draft genome sequence we easily identified the biosynthetic gene cluster of polyketomycin and other clusters encoding promising compounds. Figure 7 compares the "old" method of identifying the biosynthetic cluster by cloning of a cosmid library and elaborative screening, and the "new" method by whole genome sequencing with subsequent genome mining on a rough time scale. The new sequencing technologies and new genome mining programs speed up the whole process.
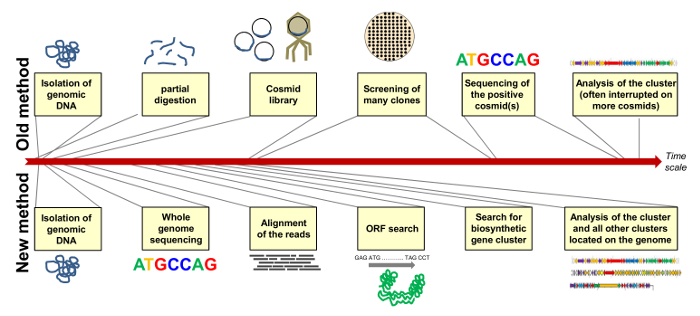
Figure 7: Comparison of the "Old" and "New" Method of Assigning a Biosynthetic Gene Cluster. The "old" method comprises cloning of a cosmid library with selection of positive clones and sequencing of the respective cosmid(s) (above); The "new" method includes whole genome sequencing and -mining to identify all secondary metabolite gene clusters located on the genome of the strain (below). Duration of single steps are shown on a rough time scale. Please click here to view a larger version of this figure.
