This work received approval from a human research ethics committee. Furthermore, informed consent was obtained from all participants involved in this study to use and publish their data.
1. Speech production
NOTE: We collected speech from a reading task on both 'L1 English-L2 BP' produced by Group 1: The American English (from the U.S.A.) Speakers (AmE-S), and on both 'L1 BP-L2 English' produced by Group 2: The Brazilian Speakers (Bra-S). See Figure 1 for a flowchart for speech production.
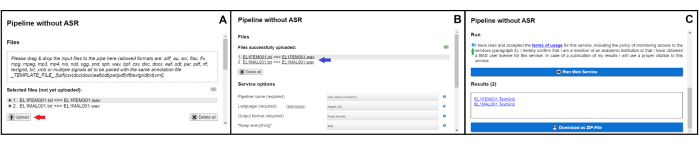
Figure 1: Schematic flowchart for speech production. Please click here to view a larger version of this figure.
- Participants
- Determine the number of participants, the language (L1 English, L2 BP; L1 BP, L2 English), the sex (female or male), the age (mean, standard deviation), the group characteristics (professionals or undergraduate students), and the L2 proficiency level (advanced or well-advanced) for each group.
NOTE: For the present research, both AmE-S and Bra-S were considered L2 proficient (both groups were qualified as B2-C136). The AmE-S had lived for two years in Brazil when the procedures were conducted. The Bra-S had lived more than two years in the U.S.A when the procedures were conducted. While living abroad, both groups used to speak their L2 for studying and working purposes at least 6 days a week for ~4-5 h a day. - Allocate the participants to a comfortable and quiet room and present the reading material for each group.
- Determine the number of participants, the language (L1 English, L2 BP; L1 BP, L2 English), the sex (female or male), the age (mean, standard deviation), the group characteristics (professionals or undergraduate students), and the L2 proficiency level (advanced or well-advanced) for each group.
- Data collection
NOTE: Speech data must be collected from a reading task in the following languages: L1-English, and L2-BP; L1-BP, and L2-English. Let the participants read the texts beforehand if necessary.- Recording procedures
- Record the speech data in a quiet place with appropriate acoustic conditions.
- Use a digital voice recorder (see the Table of Materials)37 and a unidirectional electromagnetic-isolated cardioid microphone (see the Table of Materials)38.
- Record the audio data in '.wav' form.
- Set up the sampling rate at 48 kHz and the quantization rate at 16 bits.
NOTE: The audio format and the configuration for the sampling and quantization rates described in steps 1.2.1.3 and 1.2.1.4 are applied to ensure high quality and noise reduction to preserve the spectral features used for later acoustic analysis.
- Recording procedures
- Acoustic analysis
NOTE: Divide acoustic analysis procedures into three steps: forced-alignment, realignment, and acoustic feature extraction.- Write the linguistic transcription (in a '.txt' file) for each audio file.
- Tag the pair of '.txt'/'.wav' files with the same name (i.e., 'my_file.wav'/ 'my_file.txt').
NOTE: To enhance the performance of the procedure outlined in section 1.3.7, it is highly recommended that the initial three characters of the ‘.txt/.wav’ file tags represent the Language, Dialect, or Accent, while the fourth to sixth characters denote the Sex (e.g., EL1FEM for English L1 Female). From the seventh character onward, the user should indicate the speaker number (e.g., 001 for the first speaker). Consequently, the first ‘.txt/.wav’ pair is EL1FEM001. - Create a folder for each L1-L2 language.
NOTE: A folder for L1-L2 English and a folder for L1-L2 BP. - Certify that all file pairs of the same language are in the same folder.
- Conduct the forced alignment.
- Access the web interface of Munich Automatic Segmentation (MAUS) forced aligner (webMAUS)39 at https://clarin.phonetik.uni-muenchen.de/BASWebServices/interface/Pipeline.
- Drag and drop each pair of .wav / .txt files from the folder to the dashed rectangle in Files (or click inside the rectangle, Figure 2A).
- Click the Upload button to upload the files into the aligner (see red arrow in Figure 2A).
- Select the following options in the Service options menu (Figure 2B): G2P-MAUS-PHO2SYL for Pipeline name; English (US) (for Language) if L1-L2 English data; Italian (IT) (for Language) if L1-L2 BP data.
NOTE: We chose 'Italian' for the BP data because webMAUS does not provide pretrained acoustic models for BP forced alignment. The phonetic literature poses that Italian phonology has a somewhat comparable symmetric seven-vowel inventory, just like BP40, as well as consonantal acoustic similarities41,42. - Keep the default options for 'Output format' and 'Keep everything'.
- Check the Run option box for accepting the terms of usage (see green arrow in Figure 2C).
- Click the Run Web Service button to run the uploaded files in the aligner.
NOTE: For each audio file, MAUS forced aligner returns a Praat TextGrid object (a Praat pre-formatted '.txt' file containing the annotation of words, phonological syllables, and phones based on the linguistic transcription extracted from the '.txt' file described in step 1.3.1). - Click the Download as ZIP-File button to download the TextGrid files as a zipped file (Figure 2C).
NOTE: Make sure that the zipped TextGrid files are downloaded in the same folder as the audio files. - Extract the TextGrid files for later realignment in the phonetic analysis software43.
- Conduct the realignment.
- Access and download the script for Praat VVUnitAligner44 from https://github.com/leonidasjr/VVunitAlignerCode_webMAUS/blob/main/VVunitAligner.praat.
- Certify that all file pairs of the same language and the VVUnitAligner script are in the same folder.
NOTE: A folder for the L1-L2 English files and the VVunitAligner, and a folder for the L1-L2 BP files and the VVunitAligner. - Open the phonetic analysis software.
- Click Praat | Open Praat script… to call the script from the object window.
- Click the Run button once.
NOTE: A form called Phonetic syllable alignment containing the settings for using the script will pop up on the screen (Figure 3A). - Click the Language button to choose from 'English (US),' 'Portuguese (BR),' 'French (FR),' or 'Spanish (ES)' languages.
- Click the Chunk segmentation button to choose from 'Automatic,' 'Forced (manual),' or 'None' segmentation procedure.
- Check the Save TextGrid files option to automatically save the new TextGrid files.
- Click Ok | Run buttons for a realignment of the phonetic units from step 1.3.5.7 .
NOTE: For each audio file, VVUnitAligner will generate a new TextGrid file for section 1.3.7 (Figure 3B).
- Conduct the automatic extraction of the acoustic features.
- Access and download the script SpeechRhythmExtractor45 from https://github.com/leonidasjr/SpeechRhythmCode/blob/main/SpeechRhythmExtractor.praat for automatic extraction of the prosodic-acoustic features.
- Create a new folder and put SpeechRhythmExtractor along with all pairs of audio/TextGrid files of all languages.
- Open the phonetic analysis software.
- Click Praat | Open Praat script… to call the script from the object window.
- Click the Run button only once.
NOTE: A form containing the script settings will pop up on the screen. In the boxes of the output '.txt' file names, rename the files accordingly or leave the default names. - Check the voice quality parameters option to save the Output file VQ for voice quality (Figure 3C).
NOTE: This second output file (the Output file VQ) contains the parameters of the difference between the 1st and the 2nd harmonics (H1-H2) and the Cepstral Prominence Peak (CPP)9. - Check the Linguistic target option to choose from the labels 'Language,' 'Dialect,' or 'Accent' (Figure 3C).
- Check the Unit option to choose the f0 features in Hz or in Semitones (Figure 3C).
- Set up in the values for F0 threshold, the minimum and maximum f0 thresholds (Figure 3C).
NOTE: Unless the research has specific purposes or pre-set specific audio features, it is strongly recommended to leave the parameters of step 1.3.7.9 with the default values. - Click Ok | Run for the automatic extraction of the acoustic features .
NOTE: The script SpeechRhythmExtractor returns a tab-delimited '.txt' file (Output file/ Output file VQ) containing the acoustic features extracted from the speakers.
- Statistical analysis
- Upload the spreadsheet containing the acoustic features into the R46 environment (or any statistical software/environment of choice).
- Perform Generalized Additive Models (GAMs) non-parametric statistics.
- Perform GAMs in R.
- Type the following commands and press Enter.
library(mgcv)
model = gam(the metric/prosodic-acoustic feature in analysis ~ the Language + s(the chosen metric feature, by = the Language) + other metric/prosodic-acoustic features, data = the data frame)
NOTE: We decided to perform the test statistics of the protocol in R programming language because of its increasing popularity among phoneticians (and linguists) in the academic community. R has been largely used in phonetic fieldwork research47. Keep in mind that step 1.4.2.2 contains a pseudo-code. Write the code according to the research variables.
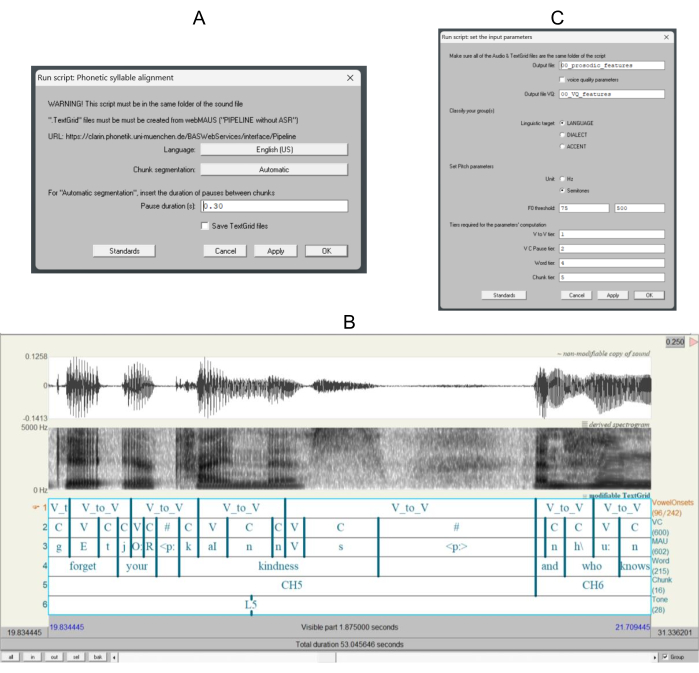
Figure 2: Screenshot from phonetic alignment using MAUS forced aligner. (A) The dashed rectangle is meant for dragging and dropping 'my_file.wav'/' my_file.txt' files or clicking inside for searching such files from the folder; the upload button is indicated by the red arrow. (B) The uploaded files from panel A (see blue arrow), the pipeline to be used, the language for the pairs of files, the file format to be returned, and a 'true/false' button for keeping all files. (C) The checkbox terms of Usage (see green arrow), the Run Web Services button, and the Results (TextGrid files to be downloaded). Please click here to view a larger version of this figure.
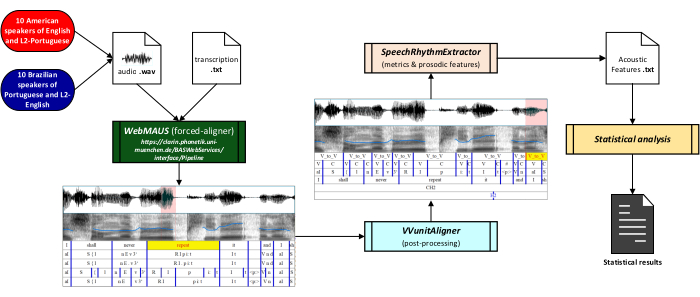
Figure 3: Screenshot of the realignment procedure. (A) Input settings form for the realignment procedure. (B) Partial waveform, broadband spectrogram with f0 (blue) contour, and six tiers segmented (and labeled) as tier 1: units of vowel onset to the next vowel onset (V_to_V); vowel onset (V_to_V); tier 2: units of vowel (V), consonant (C), and pause (#); tier 3: phonic representations V_to_V; tier 4: some words from the text; tier 5: some chunks (CH) of speech from the text; tier 6: tonal tier containing the highest (H), and the lowest (L) tone of each speech chunk produced by a female AmE-S. (C) Input settings for the automatic extraction of the acoustic features. Please click here to view a larger version of this figure.
2. Speech perception
NOTE: We carried out four voice lineups in English with American listeners and four lineups in BP with Brazilian listeners. See Figure 4 for a flowchart for speech perception.
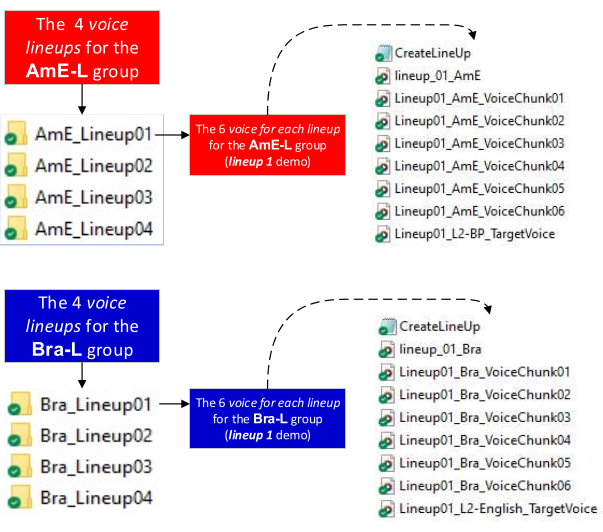
Figure 4: Schematic flowchart for speech perception. Please click here to view a larger version of this figure.
- Participants
- Choose different participants for each group from the ones who participated in the speech production protocol.
NOTE: Two groups of participants were selected for this part of the protocol: Group 1: The American English (from the U.S.A.) Listeners (AmE-L), and Group 2: The Brazilian Listeners (Bra-L). For the present research, both AmE-L and Bra-L were considered L2 proficient (both groups were qualified as B2-C136 The AmE-L had lived two years in Brazil when the procedures were conducted. The Bra-L had lived more than two years in the U.S.A when the procedures were conducted. While living abroad, both groups used to speak their L2 for studying and working purposes (at least six days a week for about 4 to 5 hours a day). - Determine the number of participants, the language (L1 English, L2 BP; L1 BP, L2 English), the sex (female or male), the age (mean, standard deviation), the group characteristics (professionals or undergraduate students) and the L2 proficiency level for each group.
- Choose different participants for each group from the ones who participated in the speech production protocol.
- The voice lineups
NOTE: Divide the voice lineups' procedures into two different steps: preparing and running the voice lineups.- Prepare four voice lineups for English and four for BP.
- Get audio files from the speakers of section 1: Speech production.
- Certify that the audio files of each language factor are in separate folders.
- Randomly choose six voice chunks in L1 English or L1 BP.
NOTE: Six voices in the lineup represent one target voice and five foils. - Choose a voice chunk in L2 English or L2 BP from one of the speakers included in step 2.2.1.3.
NOTE: The voice chunk in step 2.2.1.4 is the reference voice. Chunks must be approximately 20 s long.8. - Access and download the script for Praat CreateLineup48 from https://github.com/pabarbosa/prosody-scripts-CreateLineUp.
- Certify that the L2 reference voice, the L1 foils, and the L1 target voice are in the same folder before running the CreateLineup script (Figure 5).
- Open the phonetic analysis software.
- From the object window, click Praat | Open Praat script… to call the script.
- Click Run | Run.
NOTE: The script returns a file in the following order: (the L2 reference voice) + (the L1 target voice and the foils randomly distributed) (Figure 5).
- Running the voice lineups
- Create an online space to host the lineups on any platform of choice (e.g., SurveyMonkey. See the Table of Materials) for remotely conducting the voice lineups.
- Access the online space link.
- Upload the files returned from the CreateLineup script to the platform.
- Run the procedure before the participants to test every step.
NOTE: It is recommended to previously access the link and run the lineups to check if everything is working out normally.
- Prepare four voice lineups for English and four for BP.
- Statistical analysis
- Upload the spreadsheet containing the scores of the listeners' judgments into the R environment (or any statistical software/environment of choice).
- Perform the Kruskal-Wallis test in R.
- Type the following commands and press Enter.
model = kruskal.test(judgments ~ each voice lineup, data = the data frame)
- Perform a post-hoc Dunn's test.
- Perform Dunn's test in R.
- Type the following commands and press Enter.
library(FSA)
model = dunnTest(judgements ~ each voice lineup, data = data, method = "bonferroni")
NOTE: The codes in steps 2.3.1.2 and 2.3.2.2 are pseudo-codes (see NOTE 1.4.2.2).
- Upload the spreadsheet containing the scores of the listeners' judgments into the R environment (or any statistical software/environment of choice).
- Acoustic similarity analysis
- Select the lineups (cf. NOTE in step 2.2.1.3) that presented non-significant differences between the target and any of the foils.
- Repeat procedures of steps 1.3.1 to 1.3.7.5, and steps 1.3.7.8 to 1.3.7.10.
- Access and download the script for Python49, AcousticSimilarity_cosine_euclidean50 from https://github.com/leonidasjr/AcousticSimilarity/blob/main/AcousticSmilarity_cosine_euclidean.py.
NOTE: The script returns three matrices (in '.txt' and '.csv'): one for Cosine similarity51,52, one for Euclidean distance52,53, and one for Transformed Euclidean distance values, as well as a pairwise comparison between the target voice and each foil. - Certify that the script is downloaded in the same folder of the lineup dataset.
- Click on Open file… button to call the script.
- Click Run | Run Without Debugging buttons.
NOTE: The second Run button may be tagged as Run or Run Without Debugging or Run Script. They all execute the same commands. It simply depends on the Python environment used. - Perform voice similarity tests based on acoustic features.
NOTE: Cosine similarity (or cosine distance) is a technique applied in Artificial Intelligence (AI), particularly in machine learning in automatic speech recognition (ASR) systems. It is a measure of similarity between zero and one. A cosine similarity close to one means that two voices are quite likely to be similar. A cosine similarity close to zero means that the voices are quite likely to be dissimilar52. The Euclidean distance, often referred to as Euclidean similarity, is also widely used in AI, machine learning, and ASR. It represents the straight-line distance between two points in Euclidean space53, i.e., the closer the points (shorter values of distance), the more similar the voices are. For a clearer understanding of the reported results of both techniques, we performed a transformation of the Euclidean distance raw scores into values from zero (less voice similarity) to one (more voice similarity)54.
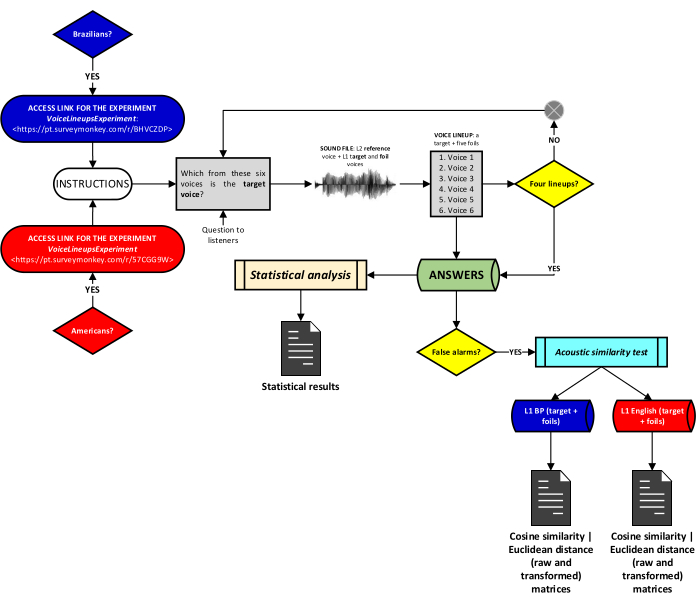
Figure 5: Directory setup for speech perception. Lineup folders. Each folder contains Six L1 voices, the L2 target voice, the "CreateLineup" script, and the voice lineup audio file (returned after running the script). Please click here to view a larger version of this figure.
Results for speech production
In this section, we described the performance of the statistically significant prosodic-acoustic features and rhythm metrics. Such prosodic features were speech, articulation, and pause rates, which are related to duration, and shimmer, which is related to voice quality. The rhythm metrics were standard deviation (SD) of syllable duration, SD of consonant, SD of vocalic or consonantal duration, and the variation coefficient of syllable duration (see the Supplemental Table S1).
The Speech rate (Figure 6A) decreases more rapidly for L1-L2 English than for L1-L2 BP, although the rate is lower for both L2s. The Speech rate is related to three metrics – SD of syllable duration (SD-S), SD of vowels (SD-V), and the syllabic variation coefficient (Varco-S). It is also important to keep in mind that both AmE-S, and Bra-S group are proficient in their L2s. It seems that such rate is affected by the higher values of syllable duration and the lower variability produced by L1-L2 BP, causing less-steeped slopes.
The Articulation rate (Figure 6D) is related to SD-S, Varco-S, as well as the Syllabic Rhythm Ratio (RR-S); the latter represents the ratio between shorter and longer syllables. Such metrics seem to affect the Articulation rate just like the affected Speech rate due to sentence length and variation in duration leading to higher L2 speech planning, and L2 cognitive load9,23,54. A higher cognitive-linguistic load may be required in the sentence length domain in a way that prosodic-acoustic parameters are affected55.
Regarding the prosodic-acoustic features of Speech and Articulation rates, our findings suggest that the more a speaker varies the duration of syllables (and vowels), the lower such rates. We hypothesize that the speech perception of both L1 and L2 BP sounds somewhat slower than L1 and L2-English, and that L1-English sounds faster than all other language levels. This fact might be linked to speech rhythm and the hypothesis that while L1-L2 BP leans toward the syllable-timed pole of the rhythm continuum, L1-L2 English moves toward the stress-timed pole21,22.
The Local shimmer, Figure 6B, is influenced by SD-S and Varco-S. For the Local shimmer, both productions of Bra-S, L1-BP, and L2-English present a somewhat monotonic trajectory as variability of syllable duration increases (SD and Varco, see Supplemental Table S1). The perception of vocal effort might be apparent when listening to the productions of Bra-S due to a low variation that ranges between 8.5 and 9 dB. Bra-S speech is affected by vocal load. L1-BP is highly affected by sentence length being less sensitive to high variations of syllable duration (BP rhythmic pattern shows less syllabic variation22,56).
The Pause rate (Figure 6C) shows that L2-English speakers produce longer pauses (from 200 ms to 375 ms) than the L1-English, L1-BP, and L2-BP ones (mean of 30 ms for L1-English, 50 ms for L1-BP, and 100 ms for L2-BP). Speech planning, in this case, might have affected L2-English production due to increased brain activity54,57. It is expected that higher language proficiency would result in a greater reading speed and span54; nevertheless, even for L2 proficient speakers, reading tasks presented more effort in higher-order cognitive aspects of foreign speech and in language processing54,57. Our findings show, at least on a preliminary basis, that L2-BP speakers may be less affected by pauses than L2-English due to differences in the rhythmic pattern of both languages.
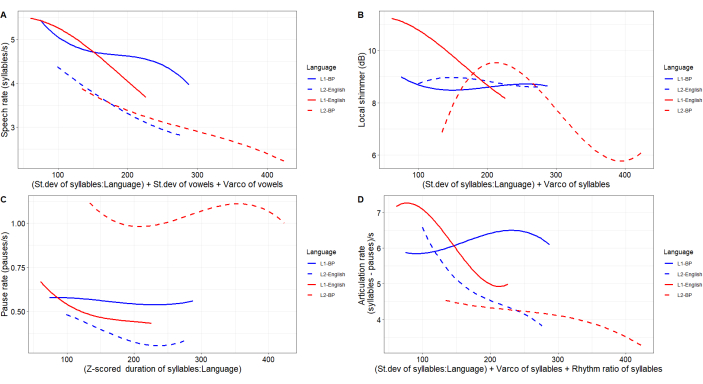
Figure 6: Generalized Additive Models for the prosodic-acoustic features. On the Y-axis, the response variable (the acoustic features to be modeled); on the X-axis, the predictor variables (the factor 'Language' and the covariates in the additive models that will provide the shape and the trajectories of the curves (i.e., the smoothing effects: 'Language + covariates'), and the product of the 'Language' and a metric feature that will provide a more accurate projection of the response variable (i.e., factor-smooth interactions: 'covariate:Language'). Abbreviation: GAMs = Generalized Additive Models. Please click here to view a larger version of this figure.
In relation to the rhythm metrics, for SD-S (Figure 7A), our findings reveal that the more a speaker varies the f0 curve and increases the speech rate, the more SD-S decreases for all the language levels (a mirror effect of Figure 6A). In the case of the SD for consonants (SD-C, Figure 7C), L1-BP, contrary to L1 English, performs low variation as Speech rate or Pause duration increases. Such SD direction is predicted since L1-English variability of syllable duration is (statistically) significantly higher than L1-BP44,58. The Varco-S (Figure 7B and Supplemental Table S1) seems somewhat correlated to the L1 and the L2 of the same language group. As the f0 variability and Speech rate increase, the Varco-S decreases for the L1-BP and seems to decrease and attenuate for L2-BP. For the English productions, while f0 variability and Speech rate increase, Varco-S increases and attenuates for L1-English and L2-English.
Regarding the SD for vowels or consonants (SD-V_C, Figure 7D and Supplemental Table S1), our results show some similarities with the Varco-S performance (Figure 7B). For instance, higher Speech rate, Pause duration, and f0 variability promote a fall-rise trajectory of the SD-V_C for L1-BP, and for the L2-BP. In English productions, while such prosodic features are higher, SD-V_C slightly decreases, attenuates for L1-English, slightly increases, and then attenuates for L2-English. The Varco-S and the SD-V_C correlation to the L1-L2 of the same language groups may be partially explained by the Lombard Effect, which refers to the alteration of acoustic parameters in speech due to background noise59.
In foreign speech, depending on the complexity of the task (e.g., read speech), speakers have used similar acoustic strategies on both L1 and L259,60. On the one hand, Marcoux and Ernestus found that f0 measures (range and median) in L2 Lombard speech suggest that L2 English speakers were influenced by their L1 Dutch61,62. On the other hand, more recent findings propose that although L2 Lombard speech is expected to differ from L1 Lombard speech due to the higher cognitive load when speaking the L2, L2 English speakers produced Lombard speech in the same direction as the L1 English speakers63. The extent to which our findings are aligned with Marcoux and Ernestus63 and diverge from Waaning59, Villegas et al.60, and Marcoux and Ernestus61,62 needs further investigation.
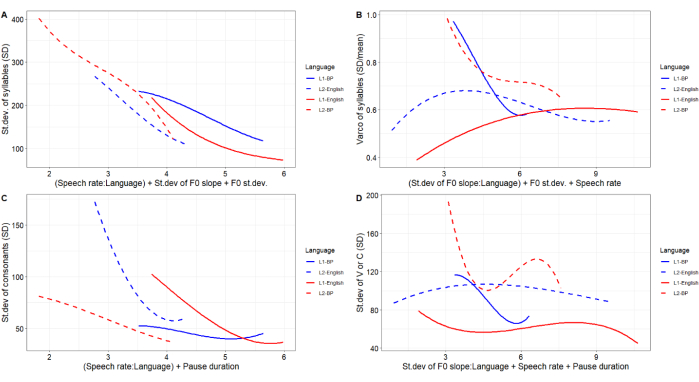
Figure 7: Generalized Additive Models for the metric features. On the Y-axis, the response variable (the metric features to be modeled); on the X-axis, the predictor variables (the factor 'Language' and the covariates in the additive models that will provide the shape and the trajectories of the curves (i.e., the smoothing effects: 'Language + covariates'), and the product of the 'Language' and a metric feature that will provide a more accurate projection of the response variable (i.e., factor-smooth interactions: 'covariate:Language'). Abbreviation: GAMs = Generalized Additive Models. Please click here to view a larger version of this figure.
Results for speech perception
In relation to the BP voice lineups, in lineup #1 (Figure 8A), the foil voice #3 was judged as being the target voice. In fact, the target voice was the voice #4. Results show no statistically significant difference (see Supplemental Table S1) between the foil #3 (83%) and the target voice #4 (71%). In lineup #2 (Figure 8B), a comparison between the target voice #3 (40%) and the foil #4 (20%) also showed no statistically significant difference (see Supplemental Table S1) for the English voice lineups. In lineup #1 (Figure 9A), there was no significant difference (see Supplemental Table S1) between the foil #2 (26%) and the target voice #4 (54%).
In the analysis of voice similarity, both the Cosine similarity (CoSim) and the Euclidean distance (EucDist, [EucDist transformed]54) showed a consistent correlation between foil #3 and the target for the BP lineup #1 (CoSim = 0.99; EucDist = 77.4, [0.93]). Correlation between foil #4 and the target was similarly strong in the BP lineup #2 (CoSim = 0.99, EucDist = 76.3, [0.93]). In the English lineup #1, correlation was consistent for CoSim (0.83(, but weak-to-satisfactory for EucDist (213.0, [0.47]. Overall, both CoSim and EucDist were satisfactory techniques in determining voice similarity. In addition, CoSim performed slightly more effectively, as addressed by Gahman and Elangovan52(see Supplemental Table S1).
In terms of similarity, what could have led to an increase in false alarms? Prosodic-acoustic features showed evidence that, although foils and target voices performed (statistically) significantly differently-with an exception for the lineups presented in Figure 8A,B and Figure 9A-listeners' choices somewhat diversified along different foils in the other lineups (Figure 8C,D, and Figure 9B-D). Such judgment seems to depend more on one (or maybe more) specific acoustic feature that speakers share than a whole class of prosodic-acoustic features. For instance, our study presented several features (co)varying between productions; nevertheless, perceptual results show the judgments' preferences for a specific foil to match the target voice8,35,64,65. Further analyses are necessary in future work.
It is noteworthy to consider the choice for a multidimensional parametric matrix for acoustic similarity66 as the one presented in this study. Our findings are aligned with previous studies that used acoustic features based on f0, VQ, and intensity9,35. Such features are remarkably suggested for speaker comparison tasks in the forensic field9,66. It is nevertheless important to highlight that in the present research, none of the foils were predicted to be similar to the target voice, although we have used a variant of McFarlane's guidelines16,17 in the preparation of the voice lineups for foreign-accented speaker recognition. Furthermore, we must emphasize that our voice lineup procedure contains important differences from McFarlane's guidelines, including stimulus length, number of voices, selection of foils (randomized here), and speech style.
To what extent prosodic-acoustic features of f0, voice quality, and intensity seem to be related to listeners' perception would highly depend on the speaking style used in the research. Here, we used reading passages. The majority of earwitness studies opt for (semi-) spontaneous stimuli as a balanced solution-e.g., the DyVis corpus67-which has been extensively employed in contemporary earwitness investigations28,68. The reason that led us to choose the reading tasks is that our corpus, at the time of the composition of this manuscript, consisted exclusively of data obtained from reading tasks. It is, however, important to acknowledge that the process of compiling a (semi-) spontaneous corpus is already in progress. Furthermore, the act of reading a story can generate a dependable level of uniformity and variation, both intra-speaker and inter-speaker. This facilitates the emphasis on prosodic or phonetic characteristics-individual or dialectal-in situations involving voice comparison. This becomes especially noticeable in instances of vocal load during the production of a foreign accent, even among proficient speakers 8,9,23,54.
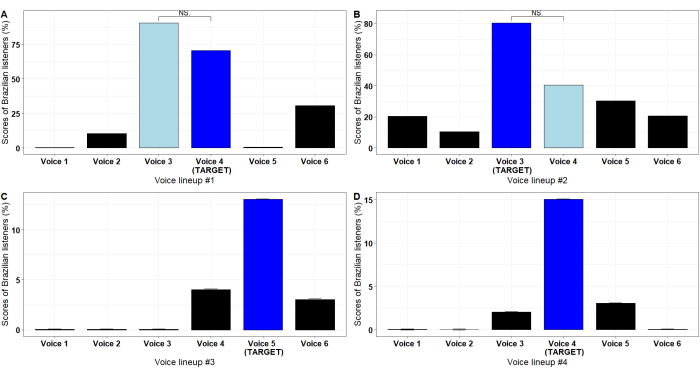
Figure 8: Bar plots containing the results for the four lineups carried out by the Brazilian listeners. (A,B) Non-significant difference between the target voice (in blue) and a foil (in light blue). (C,D) significant differences from the foils, and the target voice. Abbreviation: NS = non-significant. Please click here to view a larger version of this figure.
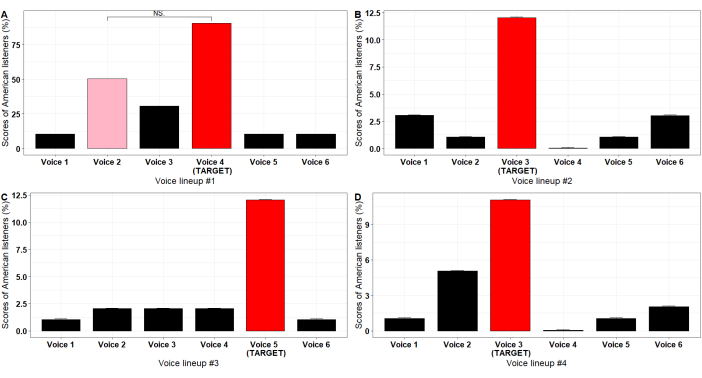
Figure 9: Bar plots containing the results for the four lineups carried out by the American listeners. (A) Non-significant difference between the target voice (in red) and a foil (in pink). (B,C,D) Significant differences from the foils and the target voice. Abbreviation: NS = non-significant. Please click here to view a larger version of this figure.
Supplementary Table S1: Speech production statistics – Generalized Additive Models (GAMs): The F-statistics (degrees of freedom), the adjusted R2 of each statistically significant prosodic-acoustic feature (Figure 6), and rhythm metric (Figure 7) per Language level, as well as the individual values of each smooth term (the covariates). Speech perception statistics: The Kruskall-Wallis χ2 statistics (degrees of freedom), the p-values, and the adjusted η2, as well as a post-hoc Dunn's test for pairwise comparison (Figure 8 and Figure 9) of each statistically non-significant difference between the pairs of target-foil voices (Figure 8A,B and Figure 9A). Acoustic similarity matrices for Cosine and Euclidean distance of each lineup. Please click here to view a larger version of this figure.
