Procedures involving human participants were approved by the University Research Ethics Committee of the University of Greenwich, following guidelines issued by the British Psychological Society.
1. Viewing of Crime Scene Video Depicting the ‘Culprit’
- Have the participant initial an information and consent form, to a study deceptively described as ‘Video Analysis’, but which lists their usual ethical rights as a research participant, and correctly states that they will view a video depicting a minor crime, and that outcomes of the study may assist future police investigations.
- Have the participant provide an anonymous personal code, and demographic data of their age, gender, and ethnicity.
- Have the participant view a randomly selected video clip on a laptop from a pool of videos of different actors, depicting good full body views and close-ups of the front and both sides of the face of the actor playing the part of a ‘culprit’ committing a minor crime (see Figure 1A and 1B for example stills from the video).


Figure 1. Stills from the crime scene video. (A, B) Two stills from the crime scene video depicting full body and facial views of the culprit (see 1.3). Please click here to view a larger version of this figure.
- Ask the participant whether they are unfamiliar with the culprit-actor (yes/no)?
NOTE: If familiar with the culprit-actor, the participant views a different culprit video. - Have the participant provide a verbal description of the culprit’s approximate age, gender, ethnicity and clothing.
- Have the participant provide a verbal rating of prospective confidence in being able to recognize the culprit (0%: no confidence to 100%: absolutely certain).
- Randomly allocate the participant to experimental condition (participant-witness vs. control), and ensure that composite creating participant-witnesses participate in Stages 2 and 7 below; controls in Stage 7 only. Ensure that the mean delay from Stage 1 to Stage 7 is equal for all participant groups.
2. Participant-witness Creation of a Facial Composite with the Assistance of an Operator
NOTE: This section of the protocol has been optimized for the holistic facial composite system, EFIT-V, but can be adapted for other software.
- Have the trained composite system operator inform the composite-creating participant-witness that they will be creating a facial composite.
- Have the operator ask the participant-witness how confident they are that they could recognize the culprit again (0% = not at all confident to 100% = highly confident).
- Have the operator ask the participant-witness how confident they are that they could construct a facial composite of the culprit (0% = not at all confident to 100% = highly confident).
- Have the operator ask the participant-witness for permission to audio record the session.
- Have the operator interview the participant-witness using elements of the Cognitive Interview (e.g., rapport building), in which the operator primarily requests the participant-witness to provide a free-recall description of what they saw in the video. Have the operator ask the participant-witness to tell him/her everything they remember about the video and the person depicted, and inform them that when they have finished, they will be asked some additional questions.
- Have the operator prompt the participant-witness with the questions listed in Table 1, but only if the description associated with that question is missing from the participant-witness’ free recall account.
| 1 | How old did the culprit appear to be? | |||||||
| 2 | What do you remember about the culprit’s hair (length, type, style, color)? | |||||||
| 3 | What do you remember about the culprit’s face (shape, length, breadth, complexion)? | |||||||
| 4 | What do you remember about the culprit’s ears (shape, size, position, lobes)? | |||||||
| 5 | What do you remember about the culprit’s nose (length, tilt, nostrils, shape, ridge)? | |||||||
| 6 | What do you remember about the culprit’s eyebrows (thickness, space, shape, color)? | |||||||
| 7 | What do you remember about the culprit’s eyes (shape, size, depth, space, shade, color)? | |||||||
| 8 | What do you remember about the culprit’s mouth/lips (width, shape, upper, lower)? | |||||||
| 9 | What do you remember about the culprit’s chin (shape, size, type)? | |||||||
| 10 | What do you remember about the culprit’s facial hair (beard, moustache, stubble)? | |||||||
| 11 | Did the culprit wear spectacles? | |||||||
| 12 | Was there anything distinctive about the culprit (marks or scars)? | |||||||
| Note: | The operator should only ask any of these questions, if the description associated with that question is missing from the participant-witness’ free recall account. | |||||||
Table 1. Cued Post Cognitive Interview Questions.
- Have the operator turn on the interface of the holistic facial composite system software on a laptop, which, as with a real investigation, stores data to ensure a reliable evidence chain.
- From the information gathered from the participant-witness during the Cognitive Interview, have the operator enter the gender, ethnicity, and age range of the described culprit into the appropriate boxes on the first screen of the composite system interface.
- Have the operator guide the participant-witness through the construction of the holistic facial composite following a procedure in which the participant-witness selects the best and rejects the worst matching images to their memory of the culprit from a 3 x 3 array of nine randomly displayed computer-generated images. If the participant-witness is not satisfied with any of the nine images, have the operator generate additional arrays.
NOTE: The ‘best’ example selected from one array always appears in the subsequent array and the similarity between faces within an array increases automatically at each step of the process.
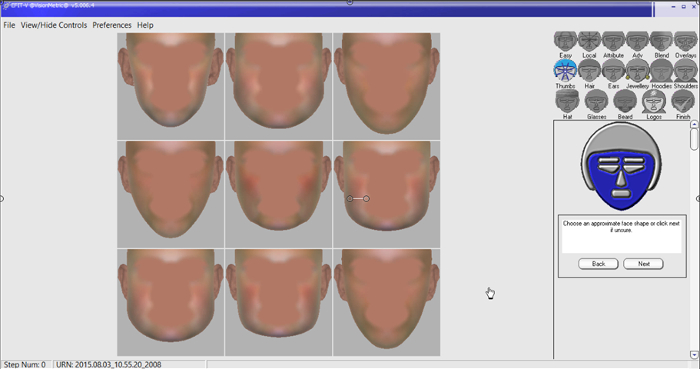
Figure 2. Facial composite construction method A: Face shape. At this stage in the facial composite construction procedure, after the operator enters basic description keywords into the holistic composite system, the participant-witness is asked to select an approximate face shape meeting their memory of the culprit from the nine images displayed on the screen, or to reject that array to produce a new display. As with the reminder of the construction process, this stage assesses recognition (see 2.9.1). Please click here to view a larger version of this figure.
- Have the participant-witness select an approximate face shape matching that of the culprit from the automatically generated first displayed array of nine images (see Figure 2), Have the operator use the interface’s TOOLS feature to enter that choice.
- Have the participant-witness select the closest matching a) nose, b) mouth, c) eye and d) eyebrow shape from subsequent arrays using the interface’s Tools feature in a similar manner to that described in 2.9.1.
- With all array faces now possessing the features entered above, but with hair initially colored grey, have the participant-witness select an appropriate hairstyle and hair color from the large database in the interface’s HAIR tool. Have the operator enter that choice (see Figure 3).
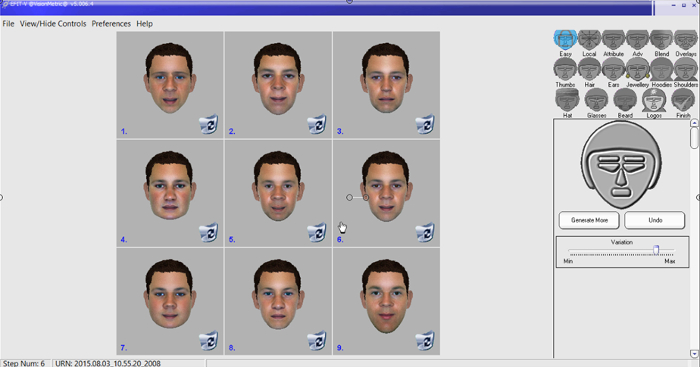
Figure 3. Facial composite construction method B: Hairstyle tool. Following selection of face shape, and facial features, the participant-witness is asked to select an approximate hairstyle from the nine images displayed on the screen, or to reject that array to produce a new display. The default hairstyle on all images is grey, until coloring is added (see 2.9.3). Please click here to view a larger version of this figure.
- Have the participant-witness select appropriate shoulders with clothing and color from the palette available in the interface’s SHOULDERS tool. Have the operator use the witness-directed controls to move, scale and rotate the neck and shoulders if necessary (see Figure 4).

Figure 4. Facial composite construction method C: Shoulders tool. Following selection of face shape, and facial features, the participant-witness is asked to select shoulders from the nine images displayed on the screen, or to reject that array to produce a new display. Clothing color and style can be manipulated and company logos or other idiosyncratic features may be added (see 2.9.4). Please click here to view a larger version of this figure.
- If they wish, have the participant-witness select clothing with or without logos (e.g., scarves, hoodies, spectacles, sunglasses), as well as facial hair (beards and moustaches) to the array faces using additional tools available on the interface. Have the operator enter these selections.
- Have the operator demonstrate the interface’s DYNAMIC OVERLAY tool to the participant-witness, which allows subtle changes to be made to the skin (e.g., wrinkles, age lines, eye-bags and shadows, prominent cheek bones, chubbiness, rough skin, acne, etc.), or to the overall face (e.g., shading). Have the operator make changes, if directed by the participant-witness.
- Have the operator magnify the face on the screen in order for the participant-witness to inspect it more closely for editing using the LOCAL ATTRIBUTES tool, which allows systematic changes to be made to the shape of the individual facial features as well as the overall shape of the face and head (e.g., stretched, rotated and warped) (see Figure 5). Have the operator make changes, if directed by the participant-witness.

Figure 5. Facial composite construction method D: Local attributes tool. After the shoulders are selected, the participant-witness views a series of facial arrays possessing faces of differing variability from each other, although variability reduces in subsequent arrays, as each ‘best’ image is chosen. At this point in creation, the participant-witness may suggest changes to specific facial features, and compare the outcome to the original unmodified image on the screen. Even though changes are made to features, the methodology still accesses holistic processes as changes are made in the context of whole face comparison (see 2.9.7). Please click here to view a larger version of this figure.
- Have the operator demonstrate the HOLISTIC ATTRIBUTES tool to the participant-witness, which allows holistic changes to be made to the face such as making it appear older or younger, more or less distinctive, and paler- or darker-skinned (Figure 6). Have the operator make changes, if directed by the participant-witness.

Figure 6. Facial composite construction method E: Holistic attributes tool. The participant-witness may also suggest changes to the holistic properties of the selected face (e.g., age, distinctiveness) by using a slider tool. Again, the outcome is compared to the original unmodified image on the screen (see 2.9.8). Please click here to view a larger version of this figure.
- Have the operator display the final composite on the screen and have the participant-witness approve this in order to save the file by clicking on the SAVE IMAGE button in the interface’s FINISH tool (see Figure 7).

Figure 7. Facial composite construction method F: Final image. In a police investigation this image would be printed, and a copy transferred to CD to be retained in the evidence bag (see 2.9.9). Please click here to view a larger version of this figure.
3. Collection of Post Composite Construction, Participant-witness Ratings of Culprit-composite Likeness
- Based on their memory of the culprit, ask the participant-witness how close a likeness the facial composite is to the culprit they saw in the video (0%: poor likeness to 100%: exact match).
- Based on their memory of the culprit, ask the participant-witness how confident they are that someone familiar with the culprit would be able to recognize them from the composite (0%: not at all confident to 100%: very confident).
NOTE: the mean rating from the scales described in 3.1 and 3.2 is calculated to produce a participant-witness self-rating of culprit-composite similarity.
4. Culprit-acquaintance Assessment of Culprit-composite Similarity
- Have a close acquaintance of the culprit (culprit-acquaintance assessor), provide an independent assessment of composite quality by viewing the composite, adjacent to two video stills from the original crime scene showing close-up facial views of the culprit, displayed as a reminder of appearance in case the culprit’s hairstyle etc. has since changed.
- Have the culprit-acquaintance assessor provide an assessment of composite-suspect likeness (0% = no similarity; 100% = highly similar).
NOTE: The mean composite rating provided by a group of assessors is calculated to produce independent ratings of composite-suspect likeness.
5. Preparation of the Video Line-ups Containing the Culprit and Foils
NOTE: This section of the protocol has been optimized for the video line-up system PROMAT, although other systems are available.
- Have a police officer create a video line-up of the culprit, at an identification suite in a police station.
- Have the police officer film a 15 sec video clip of the culprit consisting of a head-and-shoulders clip of the culprit facing the camera, turning to the left, then to the right before turning to face the camera again in standard environmental conditions (e.g., lighting, distance, camera, background). See Figure 8 for example stills extracted from the video line-up of the culprit.


Figure 8. Video lineup stills. (A,Please click here to view a larger version of this figure. B) Frontal and profile facial image stills of the culprit in the culprit-present video line-up procedure (see 5.2). Please click here to view a larger version of this figure.
- Have the police officer select videos of nine foils from a database of over 40,000, taken in the same environmental conditions and matched with the culprit for age, gender, ethnicity and ‘general appearance in life’.
NOTE: Normally only eight foils are included in a video line-up. For experimental purposes, one of the nine foils is randomly selected to replace the culprit for the culprit-absent video line-up. - Have the culprit agree that the selected foils are suitable (e.g., they possess a reasonably similar appearance to the culprit), as a suspect would have this opportunity in a real police investigation.
NOTE: Alternatively, their legal representative could have this opportunity. - Have the police officer assemble the video line-up and copy it onto a CD to allow random playback later.
6. Mock Witness Paradigm Pilot Study to Test Video Line-up Fairness
- Have a group of five pilot participants, unfamiliar with the culprit, and who do not participate in any other procedure, provide a written description of the culprit after viewing the crime scene video.
- Have another pilot participant; blind to the study design and unfamiliar with the culprit amalgamate the descriptions collected in 6.1 into a single modal description by only including descriptions of features that are described consistently by the majority of the pilot participants, while disregarding those described by a minority of pilot participants.
NOTE: The interpretation of the instructions above is left to the judgement of the pilot participant. - Have a further group of ‘mock-witness’ participants, who have also never seen the culprit, or taken part in any other procedure of the research, view an array of full-face video stills of the nine line-up members – extracted from the video line-up and to select one member based on the modal description created in 6.2.
7. Presentation of the Video Line-up and Questionnaire
- Have controls and composite creating participant-witnesses participate in this final phase of the study with the same delay between viewing the initial crime scene video for both groups.
NOTE: The controls can be provided with a distraction task (e.g., puzzles) during the period of time the participant-witnesses took to create a facial composite. - Randomly allocate the participant to view either a culprit-present or a culprit-absent video line-up.
- Have the participant read the instructions on the Cued Description Form (see Table 2), and then complete the multiple-choice or cued questions.
| Instructions | |||||
| The following is a cued description form, please try to enter comments in each section (if you can) appertaining to the particular aspect of the person (the culprit) that you saw in the original video clip. As describing a person is often a difficult task, it is important that you concentrate and stay focused for the next few minutes. Prior research has also demonstrated the importance of striving for accuracy and reporting only that which you are certain you remember. | |||||
| 1 | Ethnic appearance | ||||
| 2 | Hauteur | ||||
| 3 | Apparent age | ||||
| 4 | Gender | ||||
| Please circle one or more responses to the following questions | |||||
| 5 | Build | Fat, Proportional, Thin, Stocky, Athletic, Heavy, Other | |||
| 6 | Hair color | Dark brown, Light brown, Fair, Blonde, Grey, White, Black, Ginger, Auburn, Other | |||
| 7 | Hair type | Bald, Thinning, Receding, Straight, Curly, Wavy, Dyed, Short, Collar length, Shoulder, Very long, Wig, Length, Other | |||
| 8 | Eyes | Blue, Brown, Green, Grey, Cast, Staring, Other | |||
| 9 | Complexion | Fresh, Pale, Ruddy, Tanned, Fair, Freckled, Dark tone, Mid tone, Light tone, Other | |||
| 10 | Facial hair | Beard, Moustache, Bushy, Sideburns, Eyebrows, Other | |||
| Clothing: Enter brief description (if appropriate) | |||||
| 11 | Shoes | 12 | Socks | ||
| 13 | Trousers | 14 | Belt | ||
| 15 | Shirt | 16 | Jacket | ||
| 17 | Skirt | 18 | Dress | ||
| 19 | Jumper | 20 | Topcoat | ||
| 21 | Jewelry | 22 | Hat | ||
| 23 | Other | ||||
Table 2. Cued Description Form.
- Have the line-up administrator inform the participant that they will be attempting to identify the culprit they originally viewed in the crime scene video, in a video line-up displayed on a computer monitor.
- Have the line-up administrator warn the participant-witness that the culprit they saw in the initial crime scene video may or may not be present in the line-up.
- Have the line-up administrator start the video line-up procedure on a computer monitor consisting of a sequential display of the nine 15 sec clips which should be shown twice, with suspects and foils randomly ordered, and with a line-up member number (1–9) appearing with each video clip.
- Have the participant view the video line-up.
- On completion, have the line-up administer ask the participant whether they would like to view any part, or the whole of the line-up again.
NOTE: The participant may view part or the whole of the line-up as many times as they like. - Have the participant respond in writing to a line-up questionnaire asking whether the culprit was present or not in the line-up (yes/no), and if the response is ‘yes’ to provide the line-up member number (1-9).
- If the participant has selected a line-up member, have the line-up administrator play the video clip of that member only to ensure the participant is satisfied with their response.
- Have the participant provide a confidence estimate in their line-up decision regardless of whether they made a selection or rejected the line-up in 7.5 (0% = no confidence to 100% = absolutely certain).
8. Data Analyses
NOTE: Some of the data collected (e.g., descriptions of the culprit) in this paradigm are included primarily to ensure that procedures conform to normal police practice in England and Wales and not specifically for later analyses. Nevertheless, it would be possible to analyze these data to test for relationships between perhaps description quality and quantity, and composite quality and identification accuracy. However, these would be supplemental analyses, and the data analyses listed here are those that are most likely to be employed to investigate important experimental hypotheses.
- Use an independent-measures t-test 43 to ensure that the ratings of prospective confidence in being able to recognize the culprit, which were collected shortly after the participants viewed the crime scene video, are equal in the two experimental conditions (see 1.3.3). Check that the outcome is non-significant.
- Test hypotheses concerning the objectivity of the participant-witness’ self-assessments of their own composites, by using Pearson’s correlation coefficient tests 43 to examine the relationship between these self-assessments to their individual composites (see 3.2), with the culprit-acquaintance assessor’s ratings (see 4.5), and if collected the culprit-unfamiliar assessor ratings (see 4.6) to the entire set of composites.
- Test hypotheses related to line-up performance, use hierarchical loglinear analyses 43, or chi-square tests 43, to examine the effects of experimental condition on line-up outcomes (see 7.9).
- Use culprit-present line-ups to provide an indication of the sensitivity of an identification procedure as measured primarily by correct culprit identification rates.
- Use culprit-absent line-ups to provide an indication of the fairness of the procedure, as measured by correct line-up rejection rates.
