The speech test results indicate speech recognition ability both in quiet and in noisy conditions. The tone test results indicate the lexical tone discrimination for Mandarin lexical tones. The pitch results indicate musical discrimination ability. For speech and tone test results, all results are presented as percentages. A higher percentage score indicates a better test result. For speech tests, the results for words and sentences are presented separately. This enables the results to be analyzed and compared separately. The result for the pitch test is displayed as a visualized resolution threshold. Lower limens indicate better results. These data are easy to analyze and compare.
Spondee recognition in quiet conditions
Spondee recognition in quiet conditions significantly improved from pre-upgrade to 3 months post-upgrade (on average 16.1% better; z = 2.497; p = 0.013). The improvement was not significant from pre-upgrade to 6 weeks post-upgrade (on average 9.4% better; z = 1.735; p = 0.083) or from pre-upgrade to immediately post-upgrade (on average 5.8% better; z = 1.429; p = 0.153; Table 2 and Figure 1).
Monosyllable recognitionin quiet conditions
Monosyllable recognition in quiet conditions significantly improved from pre-upgrade to immediately post-upgrade (on average 8.2% better; z = 2.494; p = 0.013), from pre-upgrade to 6 weeks post-upgrade (on average 11.8% better; z = 2.570; p = 0.010), and from pre-upgrade to 3 months post-upgrade (on average 22.5% better; z = 2.810; p = 0.005; Table 2 and Figure 2).
Sentence recognition in quietconditions
Sentence recognition rate in quiet conditions significantly improved from pre-upgrade to 3 months post-upgrade (on average 17.8% better; z = 2.670; p = 0.008). No significant improvement was observed from pre-upgrade to 6 weeks post-upgrade (on average 13.0% better; z = 2.314; p = 0.021) or from pre-upgrade to immediate post-upgrade (on average 0.8% better; z = 0.255; p = 0.798; Table 2 and Figure 3).
Sentence recognition in noisy conditions
The pairwise comparisons from pre-upgrade to each of the post-upgrade sessions confirmed the non-significant differences in sentence recognition in noisy conditions (Wilcoxon signed-rank test: z = 1.355; p = 0.176 to z = 0.674; p = 0.500). However, sentence recognition in noisy conditions did increase on average 26% from pre-upgrade to 3 months post-upgrade (Table 2).
Tone recognition
Tone recognition significantly improved from pre-upgrade to 6 weeks post-upgrade (on average 5.0% better; t = 11.180; p < 0.001) and from pre-upgrade to 3 months post-upgrade (on average 9% better; t = 4.803; p = 0.001). No significant improvement was found from pre-upgrade to immediately post-upgrade (on average 1.6% better; t = 1.652; p = 0.133; Table 2 and Figure 4).
Musical pitch perception
Musical pitch perception significantly improved from pre-upgrade to 4 months post-upgrade (on average, 12.7 limen better; z = 2.371; p = 0.018). A non-significant improvement was observed from pre-upgrade to 6 weeks post-upgrade (on average 5.5 limen better; z = 0.840; p = 0.401), and a non-significant deterioration was observed from pre-upgrade to immediately post-upgrade (on average 7.2 limen worse; z = 0.491; p = 0.623; Table 2).
| ID | Gender | Ear implanted | Age at time of surgery (years) | Age at time of evaluation (years) | Implant type |
| S01 | M | R | 2.0 | 14.2 | COMBI 40+ |
| S02 | F | L | 1.5 | 10.3 | COMBI 40+ |
| S03 | M | L | 4.4 | 12.2 | COMBI 40+ |
| S04 | F | R | 1.6 | 9.4 | COMBI 40+ |
| S05 | M | R | 3.8 | 10.6 | COMBI 40+ |
| S06 | M | R | 4.2 | 11.1 | COMBI 40+ |
| S07 | F | R | 4.2 | 11.7 | COMBI 40+ |
| S08 | M | R | 2.3 | 9.8 | COMBI 40+ |
| S09 | M | R | 4.3 | 9.4 | COMBI 40+ |
| S10 | M | R | 3.7 | 9.3 | COMBI 40+ |
Table 1: Demographic data of all participants. Abbreviations: M = male; F = female; R = right; L = left.
| Tests | Pre-upgrade | Immediately post | 6-weeks post | 3-months post |
| Monosyllables (quiet; %) | 59.6 (±14.3) | 67.8 (±17.6) | 71.4 (±13.3) | 82.1 (±12.2) |
| Spondees (quiet; %) | 69.2 (±16.1) | 75.0 (±14.5) | 78.6 (±14.1) | 85.3 (±10.0) |
| Sentence (quiet; %) | 78.0 (±19.4) | 78.8 (±19.2) | 91.0 (±7.8) | 95.8 (±7.9) |
| Sentence (noise; %) | 59.8 (±33.78) | 70.2 (±13.5) | 80.0 (±12.9) | 85.8 (±10.7) |
| Tone recognition (%) | 75.4 (±13.3) | 77.0 (±14.8) | 80.4 (±13.1) | 84.4 (±12.3) |
| Musical pitch (quartertone) | 16.5 (±11.5) | 23.7 (±20.4) | 11.0 (±13.2) | 3.8 (±3.4) |
Table 2: Hearing performance on each test at each interval. All data are presented as mean values (± standard deviation). There are significant differences in spondee, monosyllable, and sentence recognition in quiet conditions in favor of the FS4 coding strategy (p ≤ 0.017). However, no significant differences can be found in the sentence recognitions in noisy conditions test (p > 0.05).
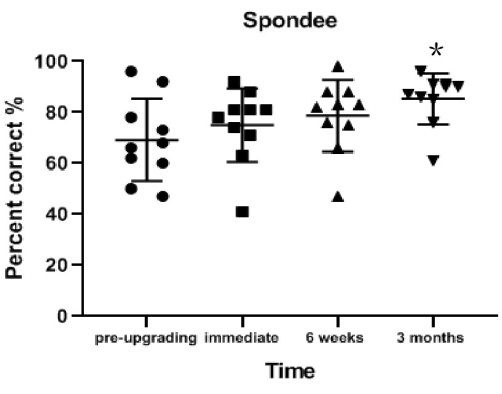
Figure 1: Spondee recognition results for each interval. Spondee recognition in quiet conditions significantly improved from pre-upgrade to 3 months post-upgrade (p = 0.013). Data are presented as mean values (± standard deviation). *p < 0.05. Circles, squares, and triangles indicate individual participant's results. Please click here to view a larger version of this figure.
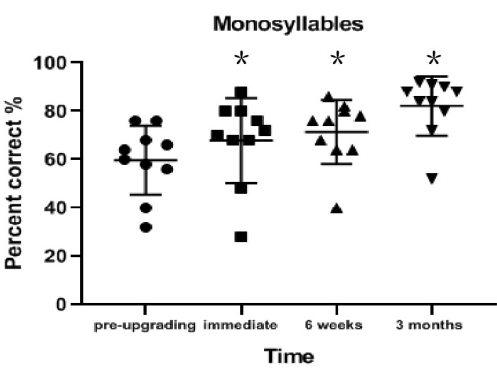
Figure 2: Monosyllable recognition results for each interval. Monosyllable recognition in quiet conditions significantly improved from pre-upgrade to immediately post-upgrade (p = 0.013), from pre-upgrade to 6 weeks post-upgrade (p = 0.010), and from pre-upgrade to 3 months post-upgrade (p = 0.005). Data are presented as mean values (± standard deviation). *p < 0.05. Circles, squares, and triangles indicate individual participant's results. Please click here to view a larger version of this figure.
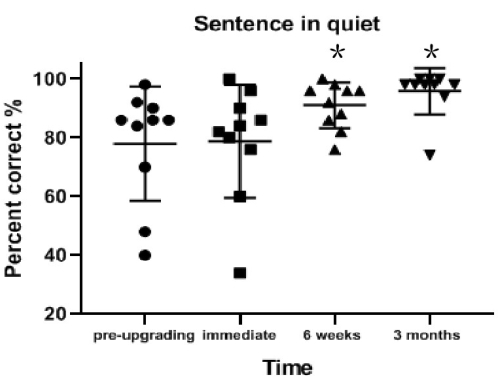
Figure 3: Sentence recognition in quiet conditions results for each interval. Sentence recognition rate in quiet conditions significantly improved from pre-upgrade to 3 months post-upgrade (p = 0.008). Data are presented as mean values (± standard deviation). *p < 0.05. Circles, squares, and triangles indicate individual participant's results. Please click here to view a larger version of this figure.
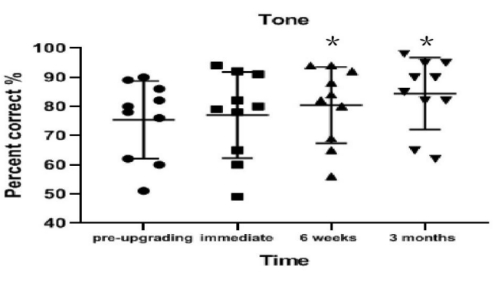
Figure 4: Tone recognition results for each interval. Tone recognition significantly improved from pre-upgrade to 6 weeks post-upgrade (p < 0.001) and from pre-upgrade to 3 months post-upgrade (p = 0.001). Data are presented as mean values (± standard deviation). *p < 0.05. Circles, squares, and triangles indicate individual participant's results. Please click here to view a larger version of this figure.
